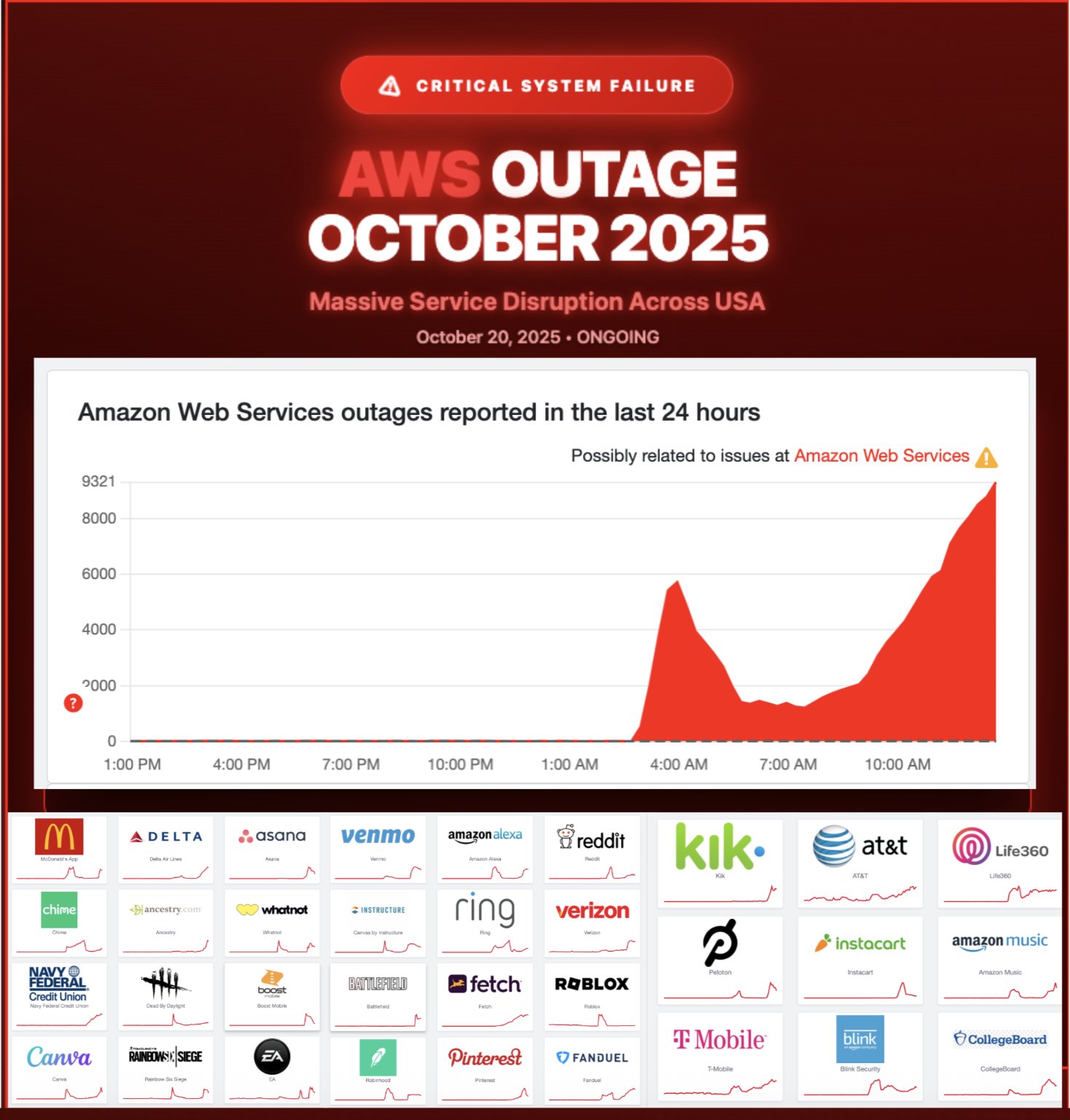
El lunes 20 de octubre de 2025, el mundo digital vivió un episodio que muchos usuarios describieron como “la Internet se detuvo por minutos (y horas)”. La caída de AWS —uno de los proveedores de infraestructura en la nube más grandes del mundo— generó interrupciones en sitios web, aplicaciones, servicios financieros, plataformas de juego y dispositivos conectados.

Este artículo se propone ofrecer un análisis técnico detallado de lo sucedido, su impacto global, las razones detrás de la falla y las lecciones que los desarrolladores, arquitectos de sistemas y responsables de negocio deben extraer.
¿Qué ocurrió? Línea de tiempo y síntomas principales
-
Alrededor de las 03:11 h ET se empezaron a registrar los primeros informes de fallas en servicios dependientes de AWS, especialmente en la región US‑EAST‑1 (Virginia del Norte).
-
AWS señaló poco después que detectaron “tasa de errores elevada y latencia aumentada” en algunos de sus servicios.
-
Un primer arreglo fue desplegado, pero no solucionó por completo el problema: varias aplicaciones como Snapchat, Fortnite, Duolingo, entre muchas otras, continuaron con interrupciones.
Hacia la tarde del mismo día AWS comunicó que el problema estaba “totalmente mitigado”, aunque explicaron que podrían persistir impactos residuales en el procesamiento de solicitudes pendientes.
Causas técnicas identificadas

Región crítica y efecto dominó
El epicentro del incidente fue la región US-EAST-1, una de las más antiguas y con mayor densidad de servicios de AWS. Debido a la elevada concentración de cargas críticas allí, una interrupción generó un efecto “dominó” que trascendió fronteras.

Problemas de DNS/internos de red
AWS indicó que el fallo se originó en un subsystema de “balanceadores de carga de red (network load balancers)” en su red interna, lo cual afectó la resolución de nombres de dominio (DNS) de algunos endpoints clave, en particular en DynamoDB, su servicio de base de datos de alta velocidad.
Dependencias y replicación incompleta
Pese a que muchos servicios están distribuidos, algunos componentes aún dependen fuertemente de la región US-EAST-1. Esto evidencia que múltiples clientes o incluso otros servicios de AWS operan con dependencias críticas encadenadas a un único “hub”.
Tiempo de recuperación y backlog
Aunque la incidencia principal fue contenida en pocas horas, AWS reconoció que el procesamiento de solicitudes pendientes (colas de eventos) provocó que algunos servicios tardaran más en restablecerse completamente.
Impacto: ¿Quiénes y cómo se vieron afectados?

A nivel de servicios populares
-
Plataformas de streaming, juegos en línea y redes sociales: Fortnite, Roblox, Snapchat, Reddit, entre otras, reportaron caídas o problemas de acceso.
-
Servicios financieros, banca y telecomunicaciones: En el Reino Unido, por ejemplo, organismos gubernamentales como HM Revenue & Customs (HMRC) sufrieron interrupciones.
-
Dispositivos conectados: Hubo reportes de usuarios que sus asistentes de voz (como Amazon Alexa), cámaras de seguridad o “smart-home” no respondían.
A nivel global
La interrupción no fue limitada a un país o región: usuarios de América, Europa, Asia y otros continentes informaron fallos simultáneos. Los datos de rastreo global (como los de Downdetector) mostraron picos de reportes en varias zonas horarias.
Consecuencias económicas y de reputación
-
Dependencia crítica: El hecho de que un solo proveedor de la nube pueda generar una disrupción tan amplia subraya el riesgo del “monocultivo”: demasiados servicios online dependen de pocas infraestructuras.
-
Impacto en la continuidad del negocio: Comercios online, aplicaciones de pago, sistemas de autenticación y otros vieron alteradas sus operaciones, generando pérdida de ingresos, quejas de usuarios y potenciales sanciones contractuales.
Cuestión regulatoria: Especialmente en el Reino Unido, la dependencia del sector público hacia AWS ha sido señalada como una vulnerabilidad que podría requerir supervisión más estricta.
Perspectiva técnica: análisis en profundidad
Arquitectura en la nube y zona crítica
La nube pública moderna se basa en regiones (geográficas) y zonas de disponibilidad (AZ), que permiten replicación y redundancia. Aunque AWS cuenta con múltiples regiones y AZ, el caso de US-EAST-1 demuestra que si la mayoría del tráfico o funciones clave dependen de una región, la redundancia se reduce.
DNS, routing y balanceadores de carga
Los balanceadores de carga (NLB, ALB en AWS) distribuyen tráfico entre instancias computacionales o servicios back-end. Si la capa de monitorización o de salud de esos balanceadores falla, las rutas de tráfico pueden colapsar o comportarse erráticamente. En este caso, AWS vinculó el incidente con sus sistemas internos de salud para esos balanceadores.
Cadena de dependencias invisibles
Muchas aplicaciones modernas no sólo ejecutan su lógica de negocio en la nube, sino que también dependen de servicios como autenticación, base de datos, CDN, colas de mensajes, etc. Una interrupción en uno de estos componentes de infraestructura puede generar fallo en cascada (efecto dominó). Los ingenieros de red lo conocen como “failure domain” amplio.
Lecciones de diseño resiliente
-
Multiregión activa-activa: No basta con tener replicación pasiva; idealmente los servicios críticos deben estar activos en más de una región.
-
Diseño de degradación grácil (“graceful degradation”): Cuando la infraestructura falla, la aplicación debe degradarse con funcionalidad mínima, en lugar de detención total.
-
Análisis de dependencias: Mapear no sólo los componentes propios, sino toda la cadena de servicios externos de los que depende.
Plan de contingencia de proveedor: Aunque AWS es fiable, un fallo grave como este demuestra que tener un proveedor alternativo (o híbrido) puede ser vital para ciertos servicios críticos.
Recomendaciones para equipos de desarrollo e infraestructura
-
Inventario de dependencias: Realice un mapeo completo de servicios externos (SaaS, PaaS, IaaS) de los que depende su aplicación.
-
Simulacros de fallo (“chaos engineering”): Pruebas planificadas de fallo en componentes seleccionados para validar cómo su sistema responde ante interrupciones.
-
Arquitectura multirregión y multi-proveedor: En la medida de lo posible, diseñar la infraestructura para poder cambiar entre regiones o proveedores sin interrupciones críticas.
-
Módulos de degradación: Asegúrese de que, en caso de fallo, partes de la aplicación sigan operativas (por ejemplo: modo lectura sólo, buffering de transacciones, respaldo local).
Monitoreo, alertas y comunicación: Establezca alertas tempranas no sólo de disponibilidad sino de latencia y tasa de errores; y tenga un plan de comunicación transparente con usuarios en caso de interrupción.
Conclusión
La caída global del 20 de octubre de 2025 de AWS fue un recordatorio contundente de que, aunque la nube pública ha transformado radicalmente la infraestructura de TI, también ha introducido nuevos riesgos de concentración. La dependencia de una región crítica, un fallo interno de balanceadores/DNS y la propagación en cadena llevaron a que una buena parte de Internet se viera afectada.
Para los desarrolladores, arquitectos y responsables de negocio, el mensaje es claro: la resiliencia ya no es opcional. No se trata únicamente de tener respaldo, sino de anticipar fallas, diseñar para el peor caso y responder con agilidad. En un mundo digital donde el servicio “siempre activo” es la expectativa, una sola interrupción puede generar consecuencias globales.






