Se ha dado a conocer el lanzamiento de la nueva versión de Git 2.48
la cual incluye múltiples optimizaciones y mejoras. Este lanzamiento
destaca por la inclusión de Meson como nuevo sistema de compilación,
mejoras de rendimiento y soporte, asi como también correcciones y la
solución al problema de las pérdidas de memoria.
En Git 2.48 se ha introducido el sistema de compilación Meson que
se suma a GNU Make y CMake. Meson ofrece un proceso de construcción más
limpio y accesible, especialmente para quienes no están familiarizados
con la complejidad de Make, al mismo tiempo que conserva la
compatibilidad multiplataforma. Sin embargo, no se contempla la
eliminación de las herramientas tradicionales de compilación, asegurando
continuidad para los usuarios actuales.
Otra de las novedades que se destaca es la incorporación de soporte para implementaciones alternativas del algoritmo SHA-1 en el cálculo de sumas de verificación. Por
defecto, las nuevas implementaciones protegen contra ataques como
SHAttered y Shambles, aunque a costa de un menor rendimiento. Para
tareas donde la seguridad criptográfica no es prioritaria, se han
introducido opciones que aceleran el cálculo sacrificando dicha
protección. Esta flexibilidad permite a los usuarios adaptar el
rendimiento según sus necesidades específicas, como lo demuestran los
aumentos registrados en GitHub durante operaciones de clonación.
Además de ello, se menciona que se ha añadido una nueva funcionalidad al comando range-diff
que permite analizar diferencias entre el estado final de una fusión y
los datos reflejados tras resolver conflictos. Esto facilita la
comprensión de los cambios realizados en procesos complejos de
integración, haciendo que la herramienta sea aún más útil para
desarrolladores que trabajan en grandes proyectos colaborativos.
También en Git 2.48 se ha abordado el problema de las pérdidas de memoria, algo que aunque históricamente no había sido una preocupación significativa para Git, cobra importancia dado los procesos de larga duración
donde las funcionalidades internas se transforman en bibliotecas
reutilizables. La posibilidad de ejecutar pruebas con detección de
pérdidas asegura mayor estabilidad y confianza en este tipo de
escenarios.
Por otra parte, el comando «git for-each-ref», incorpora una optimización para la gestión de referencias en el repositorio.
Esta mejora combina controladores de filtrado y formato de salida no
solo para listas sin ordenar, sino también cuando se utiliza la opción
«–sort», mejorando la eficiencia en escenarios donde el orden es
importante.
En cuanto a «reftable», se ha trabajado en un almacenamiento más eficiente para referencias de ramas y etiquetas,
utilizando bloques que aceleran la búsqueda y reducen el consumo de
memoria. Este sistema ahora es menos dependiente de bibliotecas externas
como libgit, lo que simplifica las dependencias al compilar Git.
Además, se han introducido mecanismos para manejar adaptativamente
errores de memoria insuficiente, evitando fallos críticos en estas
situaciones.
La funcionalidad de clonación parcial también ha recibido mejoras,
resolviendo problemas relacionados con bucles y corrupción en el
repositorio tras ejecutar el comando «git gc». Este avance es
especialmente importante para quienes trabajan con repositorios
fragmentados o de gran tamaño, ya que garantiza la integridad de los
datos.
El comando «git fetch» también ha sido mejorado, ya
que ahora, si la referencia «refs/remotes/origin/HEAD» no existe en el
sistema local pero está presente en el remoto, esta se sincroniza
automáticamente. Para mayor control, se ha introducido la configuración
«remote.origin.followRemoteHead», que regula esta sincronización.
Otro cambio significativo se encuentra en el comando «git rebase –rebase-merges», que ahora prioriza el uso de nombres de ramas como etiquetas,
mejorando la claridad durante la reorganización de commits. Por otro
lado, los comandos «git notes add» y «git notes append» han incorporado
el indicador «-e», que permite editar notas directamente en un editor
externo definido por la variable de entorno GIT_EDITOR.
Por último y no menos importante, en términos de compatibilidad y estándares, Git 2.48 amplía su soporte para GCC 15 y el estándar C23,
asegurando que se mantenga actualizado con las herramientas de
desarrollo modernas. Sin embargo, se ha discontinuado el soporte para
versiones antiguas de libcURL y Perl.
Finalmente, si estás interesado en poder conocer más al respecto, puedes consultar los detalles en el siguiente enlace.
Las APIs, o Interfaces de Programación de Aplicaciones, son un
componente esencial en el mundo de la tecnología y el desarrollo de
software. Una API permite que dos aplicaciones diferentes se comuniquen
entre sí, intercambiando datos y funciones de manera estructurada. Pero,
¿qué significa esto en la práctica y por qué son tan importantes?
Definición de API
En su esencia, una API es un conjunto de reglas y protocolos que
permiten que diferentes programas de software interactúen. Piensa en una
API como un mensajero que toma una solicitud de una aplicación, la
lleva al sistema deseado y luego devuelve una respuesta. Este proceso
ocurre de manera transparente para los usuarios finales, lo que facilita
la integración entre aplicaciones.
¿Cómo funcionan las APIs?
El funcionamiento de una API se puede entender a través de tres pasos fundamentales:
Solicitud: Una aplicación envía una solicitud a la API. Esto incluye información sobre qué datos o funcionalidad necesita.
Procesamiento: La API recibe la solicitud, la interpreta y la envía al sistema o base de datos correspondiente.
Respuesta: La API devuelve la información o resultado solicitado a la aplicación que hizo la petición.
Por ejemplo, cuando usas una aplicación meteorológica, esta se
comunica con una API para obtener datos climáticos de un servidor
remoto.
Tipos de APIs
Existen diferentes tipos de APIs, diseñados para diversas aplicaciones:
APIs abiertas (o públicas): Disponibles para cualquier desarrollador, fomentan la innovación y la creación de aplicaciones.
APIs internas: Usadas dentro de una organización para conectar sistemas internos.
APIs asociadas: Compartidas entre socios comerciales para integraciones específicas.
APIs compuestas: Combinan varias APIs para realizar tareas más complejas.
Beneficios de las APIs
El uso de APIs trae una serie de ventajas, entre las que destacan:
Facilidad de integración: Las APIs permiten conectar múltiples aplicaciones y servicios de manera eficiente.
Automatización: Reducen la necesidad de interacciones manuales al automatizar flujos de trabajo.
Escalabilidad: Ayudan a las empresas a escalar sus operaciones al facilitar el acceso a recursos y funcionalidades.
Innovación acelerada: Fomentan el desarrollo de nuevas aplicaciones y servicios al permitir el acceso a herramientas y datos preexistentes.
Ejemplos de uso de APIs
Las APIs son parte integral de nuestra vida diaria, aunque no siempre las notemos. Algunos ejemplos incluyen:
Redes sociales: Integraciones para compartir contenido desde otras aplicaciones.
Pagos en línea: APIs de servicios como PayPal o Stripe para realizar transacciones seguras.
Mapas y navegación: Servicios como Google Maps permiten a otras aplicaciones integrar mapas y direcciones.
Conclusión
Las APIs son una piedra angular en el mundo digital moderno.
Facilitan la conectividad, la eficiencia y la innovación, permitiendo
que las aplicaciones trabajen juntas de manera armoniosa. Si eres un
desarrollador o una empresa que busca optimizar procesos y ofrecer
mejores servicios, comprender y aprovechar las APIs puede marcar una
gran diferencia.
¡Adéntrate en el mundo de las APIs y descubre cómo transformar tus proyectos!
GitHub Codespaces se puede configurar, lo que le permite crear un
entorno de desarrollo personalizado para el proyecto. Al configurar un
entorno de desarrollo personalizado para su proyecto, puede tener una
configuración de codespace repetible para todos los usuarios del
proyecto.
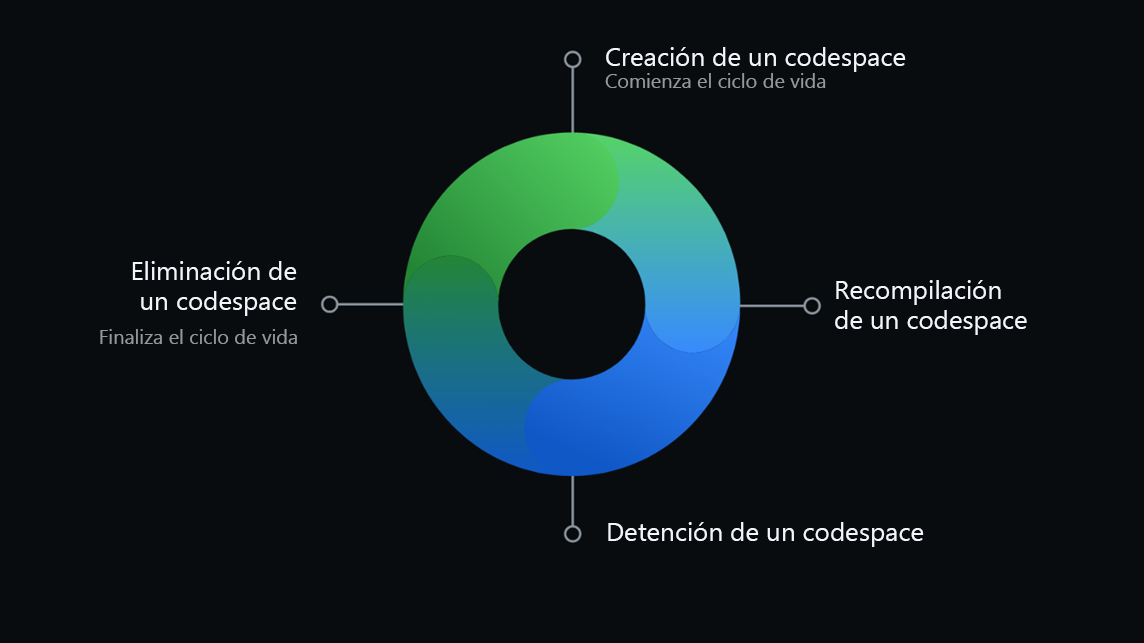
El ciclo de vida de un codespace comienza cuando se crea y termina
cuando se elimina. Puede desconectarse y reconectarse a un codespace
activo sin que esto afecte a sus procesos en ejecución. También puede
detener y reiniciar un codespace sin perder los cambios que haya
realizado en su proyecto.
Crear un codespace
Puede crear un codespace en GitHub.com, en Visual Studio Code o en la
CLI de GitHub. Existen cuatro formas de crear un codespace:
Desde una plantilla de GitHub o desde cualquier repositorio de plantillas de GitHub.com para iniciar un nuevo proyecto.
Desde una rama del repositorio para el trabajo de nuevas características.
Desde una solicitud de cambios abierta para explorar el trabajo en curso.
Desde una confirmación en el historial de un repositorio para investigar un error en un punto específico del tiempo.
Puede usar un codespace temporalmente para probar código o volver al
mismo codespace para realizar trabajo de características de larga
duración.
Puede crear más de un codespace por repositorio o incluso por rama.
Sin embargo, hay límites respecto al número de codespaces que puede
crear y ejecutar al mismo tiempo. Si alcanza el número máximo de
codespaces e intenta crear otro, aparece un mensaje que indica que se
debe quitar o eliminar un codespace existente para poder crear uno
nuevo.
Puede crear un nuevo codespace cada vez que desarrolle en
GitHub Codespaces o mantener un codespace de larga duración para una
característica. Si va a iniciar un proyecto nuevo, cree un codespace a
partir de una plantilla y publíquelo en un repositorio de GitHub más
adelante.
Al crear un codespace cada vez que se trabaja en un proyecto, debe
enviar los cambios periódicamente para asegurarse de que todas las
confirmaciones nuevas estén en GitHub. Al usar un codespace de larga
duración para un proyecto nuevo, incorpore los cambios desde la rama
predeterminada del repositorio cada vez que empiece a trabajar en el
codespace. Esto permite al entorno obtener las últimas confirmaciones.
El flujo de trabajo es similar a trabajar con un proyecto en una máquina
local.
Los administradores de repositorios pueden habilitar las
precompilaciones de GitHub Codespaces para que un repositorio acelere la
creación de un codespace.
Para ver un tutorial y una guía detallados, consulte los recursos Guía para principiantes para aprender a codificar con GitHub Codespaces y Desarrollar en un codespace que se encuentran en la unidad Resumen al final de este módulo.
Proceso de creación de un codespace
Al crear un codespace de GitHub tienen lugar cuatro procesos:
Se asignan al codespace una máquina virtual y almacenamiento.
Se crea un contenedor.
Se establece una conexión con el codespace.
Se realiza una configuración posterior a la creación.
Guardar cambios en un codespace
Cuando se conecta a un codespace a través de la web, se habilita de
forma automática la opción de autoguardado para guardar los cambios
cuando haya transcurrido una cantidad de tiempo específica. Al
conectarse a un codespace a través de Visual Studio Code en ejecución en
el escritorio, debe habilitar Autoguardado.
El trabajo se guarda en una máquina virtual en la nube. Puede cerrar y
detener un codespace y volver al trabajo guardado más adelante. Si
tiene cambios sin guardar, recibirá un mensaje para guardarlos antes de
salir. Sin embargo, si el codespace se elimina, se pierde el trabajo.
Para guardar el trabajo, debe confirmar los cambios y enviarlos al
repositorio remoto o publicar el trabajo en uno nuevo si ha creado el
codespace a partir de una plantilla.
Apertura de un codespace existente
Puede volver a abrir cualquiera de los codespaces activos o detenidos
en GitHub.com, en un IDE de JetBrains, en Visual Studio Code o mediante
la CLI de GitHub.
Para reanudar un codespace existente, puede ir al repositorio donde existe el codespace, presionar la tecla «,» en el teclado y seleccionar Reanudar este codespace o bien abrir https://github.com/codespaces en el explorador, seleccionar el repositorio y, a continuación, seleccionar el codespace existente.
Tiempos de espera de un codespace
Si un codespace está inactivo o si sale del codespace sin detenerlo
de forma explícita, la aplicación agota el tiempo de espera después de
un período de inactividad y deja de ejecutarse. El tiempo de espera
predeterminado es después de 30 minutos de inactividad. No se puede
personalizar la duración del período de tiempo de espera para los nuevos
codespaces. Cuando se agota el tiempo de espera de un codespace, se
preservan los datos de la última vez que haya guardado los cambios.
Conexión a Internet al usar GitHub Codespaces
Un codespace requiere conexión a Internet. Si la conexión a Internet
se pierde mientras trabaja en un codespace, no podrá acceder a este. Sin
embargo, cualquier cambio pendiente de confirmación se guarda. Al
restablecer la conexión a Internet, puede acceder al codespace en el
mismo estado que se dejó cuando se perdió la conexión.
Si tiene una conexión de internet inestable, debe confirmar e insertar los cambios frecuentemente.
Cerrar o detener un codespace
Si sale del codespace sin ejecutar el comando para detenerlo (por
ejemplo, cierra la pestaña del explorador) o si deja el codespace en
ejecución sin interacción, el codespace y sus procesos en ejecución
continuarán durante el período de tiempo de espera de inactividad. El
período de tiempo de espera de inactividad predeterminado es de 30
minutos. Puede definir su configuración de tiempo de espera personal
para los codespaces que cree, pero una directiva de tiempo de espera de
la organización puede invalidarla.
Solo los codespaces en ejecución conllevan cargos de CPU. Un codespace detenido solo conlleva costos de almacenamiento.
Puede detener y reiniciar un codespace para aplicar cambios. Por
ejemplo, si cambia el tipo de máquina que se usa para el codespace, debe
detenerlo y reiniciarlo para que el cambio surta efecto. Al cerrar o
detener su codespace, todos los cambios pendientes de confirmación se
preservan hasta que vuelva a conectarse al codespace.
También puede detener el codespace y elegir restablecerlo o eliminarlo si encuentra un error o algo inesperado.
Recompilación de un codespace
Puede recompilar el codespace para implementar cambios en la
configuración de contenedor de desarrollo. Para la mayoría de los usos,
puede crear un codespace como alternativa a recompilar uno. Al
recompilar su codespace, las imágenes de la memoria caché aceleran el
proceso de recompilación. También puede realizar una recompilación
completa para borrar la memoria caché y recompilar el contenedor con
imágenes nuevas.
Al recompilar el contenedor en un codespace, los cambios realizados
fuera del directorio /workspaces se borran. Los cambios realizados
dentro del directorio /workspaces, incluido el clon del repositorio o la
plantilla desde la que ha creado el codespace, se conservan al
recompilar.
Eliminar un codespace
Puede crear un codespace para una tarea determinada. Después de
enviar los cambios a una rama remota, puede eliminar ese codespace de
forma segura.
Si intenta eliminar un codespace con confirmaciones de GIT sin
enviar, el editor le notifica que tiene cambios que no se han enviado a
una rama remota. Puede enviar cualquier cambio deseado y, después,
eliminar su codespace. También puede continuar con la eliminación del
codespace y los cambios pendientes de confirmación o exportar el código a
una rama nueva sin crear un codespace.
Los codespaces detenidos que permanecen inactivos durante un período
de tiempo especificado se eliminan automáticamente. Los codespaces
inactivos se eliminan después de 30 días, pero puede personalizar los
intervalos de retención de codespaces.
Es muy importante colocar los valores de los atributos entre comillas
dobles. En caso de no colocar las comillas dobles, el procesador le
indicará que hubo un error.
ESTRUCTURA DE WEBREPORT-ML
Un reporte escrito en WEBREPORT-ML comienza y termina con la marca reporte, indicando que se trata de un reporte a realizar en el lenguaje.
<reporte>
Cuerpo del documento
</reporte>
Dentro del elemento reporte se encentran varios elementos primarios, tales como:
descripcion
salida
conexion
consulta
titulo
cabecera
detalles
pie-de-pagina
Ejemplo:
<?xml version=»1.0″ encoding =»iso-8859-1″?>
<reporte>
<conexion/>
<consulta>
Contenido de la consulta SQL
</consulta>
<margenes />
<salida/>
<titulo>
Reporte de Productos
</titulo>
<descripcion>
Contenido de la descripcion
</descripcion>
<cabecera>
<fila>
<campo> </campo>
</fila>
</cabecera>
<detalles>
<fila>
<campo/>
</fila>
</detalles>
<pie-de-pagina>
<fila>
<campo> </campo>
</fila>
</pie-de-pagina>
</reporte>
DESCRIPCIÓN DE LOS ELEMENTOS DEL LENGUAJE REPORT-ML
Elemento descripcion
El elemento descripcion se utiliza para colocar una información descriptiva acerca de los que se trata el reporte. Ejemplo:
<descripcion>
Este es un reporte para los empleados de la compañía
</descripcion>
Elemento margenes
El elemento margenes se utiliza para especificar cada uno de los márgenes para el documento del reporte y consta de los siguientes atributos:
Atributo margen-superior
Atributo margen-inferior
Atributo margen-izquierdo
Atributo margen-derecho
Elemento salida
El elemento salida se utiliza para especificar el formato en
el que se desea que se muestre el reporte, así como la ruta en donde se
guardará el reporte. Contiene los siguientes atributos:
Atributo formato
Atributo archivo
*Atributo formato
El atributo formato especifica el formato en el que se desea que se imprima el reporte. Los tipos de formatos disponibles en WEBREPORT-ML son:
Html
PDF
DocBook
*Atributo archivo
El atributo archivo especifica la ruta en donde se desea
guardar el reporte. Es importante que el usuario especifique una ruta
en donde se guardará su reporte para que al momento de terminar de
exportar los datos al formato requerido, sabrá que el reporte se alojará
precisamente en el lugar que él indicó.
Elemento conexion
El elemento conexion se utiliza para especificar los esquemas de conexión con la base de datos. Contiene los siguientes atributos:
*Atributo conector
El atributo conector especifica el motor de la base de datos a utilizar.
Ejemplo:
conector=»sun.jdbc.odbc.JdbcOdbcDriver»
*Atributo url
El atributo url la ruta de la base de datos de la siguiente manera:
jdbc:odbc:Base_de_Datos
Elemento consulta
El elemento consulta especifica el contenido de la consulta SQLque se va a utilizar para generar nuestro reporte.
Ejemplo:
<consulta>
select * from tabla
</consulta>
Elemento titulo
El elemento titulo se utiliza para el título del reporte.
Elemento cabecera
El elemento cabecera se utiliza para los títulos de cada campo del reporte. Contiene un elemento anidado fila el cual hace referencia a las filas deseadas por el usuario; ésta a su vez contiene un elemento anidado campo, que especifica el número de campos (columnas) que el usuario desea para esa fila.
Ejemplo:
<cabecera>
<fila>
<campo tipo=”texto”>
Nombre
</campo>
<campo tipo=”texto”>
Apellido
</campo>
</fila>
</cabecera>
Para el ejemplo anterior se mostrará, en una misma fila, varios
campos con los títulos para el reporte y quedaría de la siguiente forma:
Nombre
Apellido
Elemento detalles
El elemento detalles constituye uno de los elemento más
importantes del reporte, pues es ahí en donde se especifican cada uno de
los campos de la base de datos que se mostraran en el reporte, así
como también se realizan las fórmulas que se desean hacer para el
reporte. Las fórmulas deben codificarse en el lenguaje Java Script.
Existen dos tipos de campos diferentes a los anteriormente descritos,
que se utilizan en el detalle:
El tipo de campo bd
El tipo de campo formula
El tipo de campo bd, se utiliza
para especificar cada uno de los campos de la base de datos que el
usuario desea mostrar en el reporte. Para este tipo de campo, existe un
atributo llamado nombre, el cual especifica
el nombre del campo de la base de datos a extraer para el reporte. Cada
vez que el usuario especifique el tipo de campo bddebe especificar en el atributo nombre el nombre del campo de la base de datos.
Ejemplo:
<detalles>
<fila>
<campo tipo=”bd” nombre=”cedula”/>
<campo tipo=”bd” nombre=”nombre”/>
<campo tipo=”bd” nombre=”apellido”/>
</fila>
</detalles>
El tipo de campo formula,se utiliza para las distintas fórmulas que se desean hacer para el reporte.
Ejemplo:
<detalles>
<fila>
<campo tipo=”formula”>
value = parseInt(query.get(«CANTIDAD»)) * parseInt(query.get(«PRECIO»));
</campo>
</fila>
</detalles>
*Atributo formato
El atributo formato especifica el formato numérico a utilizarse. Este atributo hace parte del elemento anidado campo y se utiliza en caso de que se utilicen números y se les quiera aplicar algún tipo de formato.
Para el ejemplo anterior, se mostrarán todos los registros del campo Valor, correspondiente
al valor unitario de X producto y se le aplica el tipo de formato
$#.##0,00 así como el estilo de letra negrita. El resultado de uno de
los registros del campo valor, quedaría de la siguiente forma: $ 2,052,000.00
Elemento pie-de-pagina
El elemento pie-de-pagina se utiliza para colocar algún
contenido al final del reporte, como funciones para hallar el total de
un determinado campo de la base de datos, ó el gran total de algún total
hallado por medio de las fórmulas descritas en el detalles. Contiene un
elemento anidado fila el cual hace referencia a las filas deseadas por el usuario; ésta a su vez contiene un elemento anidado campo, que especifica el número de campos (columnas) que el usuario desea para esa fila.
Los tipos de campo utilizados en el pie-de-pagina son:
text
total
El campo total se utiliza única y exclusivamente en el
elemento pie-de-pagina. Este tipo de campo especifica la función a
llevar a cabo para hallar el total de un determinado campo de la base de
datos ó para hallar un resultado total de cada uno de los resultados
hallados en la fórmula escrita en el detalle.
También existe un atributo que va de la mano con el tipo de campo total y es el atributo funcion, el cual se explica a continuación.
*Atributo funcion
El atributo funcion especifica la función a utilizarse en el pie-de-pagina y depende del tipo de campo total. Los tipos de funciones disponibles para la el atributo funcion del pie-de-pagina son las siguientes:
Si el usuario va a utilizar en el reporte caracteres propios del
alfabeto español, tales como la letra ñ, tildes, etc, deberá incluir el
siguiente atributo al principio de la creación del reporte:
Para la instalar WEBREPORT-ML, el usuario deberá copiar la carpeta reportml que se encuentra el CD de instalación en el directorio Coligo Fuente, al disco duro y después crear un nuevo Context en el servidor de Apache TOMCAT, el alias debe ser /reportml y el documento base debe ser c:/reportml.
Para desinstalarlo, solo se elimina el Context del servidor y se borra el directorio de la raíz de C: .
Cabe recordar que dentro del directorio reportml se encuentra el directorio waren el cual se encuentra el archivo WebReport.war. Para instalar este archivo, hay dos opciones:
OPCION 1:
1) Copiar el fichero war a TOMCAT / webapps
2) Arrancar el servidor
3) La instalación es automática y crea un nuevo directorio con los contenidos del war.
OPCION 2:
1) Crear la aplicación Web descomprimida en webapps siguiendo el formato estándar.
2) Añadir en TOMCAT / conf / server.xml un nuevo contexto que apunte a nuestro directorio:
NOTA: En su momento este proyecto fue diseñado y
desarrollado bajo windows, sin embargo, puede funcionar con sistemas
operativos linux y macOs. Puedes acceder a todo el proyecto a través de
su repositorio oficial en github: https://github.com/rrcyber/WebReportML/
Este proyecto fue escrito en PHP, con el fin de permitir a los
estudiantes en ciberseguridad, simular ataques DDoS. La herramienta ha
sido escrita para fines educativos, esto quiere decir que los
desarrolladores no se hacen responsables del mal uso que se le de a
ésta.
Hace un tiempo desarrollé un proyecto con Java y mySQL, el cual se
basa en el registro y autenticación de usuarios a través del lector de
huellas DigitalPersona 4500.
El proyecto está diseñado y desarrollado con Java, puede ser abierto a
través de netbeans o eclipse. Funciona tanto en Windows como en Linux.
El motor de base de datos es mySQL y utiliza el SDK de DigitalPersona.
Qué es Jarvis? Es un sistema de información, diseñado para
automatizar procesos de consolidación de información, recorriendo la
cuenta de correo electrónico autorizada para envío y recibo de
notificaciones, consumir los servicios web del sistema Andess y procesar
los datos a través del motor de base de datos postgreSQL.
Estoy trabajando el desarrollo de unas aplicaciones en python que
permitan realizar transacciones con blockchain y además que aprendan a
diseñar su propia criptomoneda.
Actualmente python se ha convertido en el lenguaje de programación
más popular del siglo XXI, por encima de lenguajes como php y java.
En mi consigna de retomar el desarrollo de aplicaciones o desarrollo
de software (como lo conocen en la vieja escuela) y de convertirme en un
desarrollador Full Stack, comencé a estudiar python de forma
autodidacta.
En este breve artículo les traigo un pequeño servidor web escrito en
python, el cual simplemente lo desarrollé con ayuda de tutoriales y
manuales en internet, además de seguir la guía práctica de python https://docs.python.org/es/3/index.html
Sin más preámbulos, les comparto el funcionamiento del servidor:
Te invito a revisar el código fuente compartido en mi repositorio oficial de github https://github.com/rrcyber/webserver_python y es distribuido bajo licencia GNU General Public License v3.0.
Hace un par de años me decidí volver a retomar la senda del desarrollo
de aplicaciones de software después de muchos años de estar alejado de
esta área de mi carrera profesional.
Soy ingeniero de sistemas graduado hace casi 20 años. Recién me
gradué decidí que lo único en lo que quería trabajar era en el
desarrollo de aplicaciones de software. En la universidad siempre me
caracterice por desarrollar y entender la lógica de los sistemas de
información. Aprendí a programar en los lenguajes de programación de la
epoca: C/C++, Java, Delphi, Assembler, Prolog, Cammel, PHP, Visual
Basic.
De todos esos lenguajes de programación me encaminé por el desarrollo
de aplicaciones en Java. Diseñé y desarrollé mi proyecto de grado en la
universidad sobre este lenguaje de programación y ya como profesional
unos 7 años después comencé a diseñar un sistema de información basado
en biometria, el cual consistió en desarrollar un sistema de información
que permite la autenticacion y control de ingresos de usuarios a través
de huella digital.
Hoy en día puedo decir que trabajo y conozco nuevos lenguajes de
programación, entre los que se destacan a nivel de backend: python, php,
nodejs; mientras que a nivel de frontend se destaca js y el mismo php.
Estoy en proceso de aprender nuevos lenguajes de programación como
Ruby, TypeScript, entre otros. Pienso que un desarrollador full stack,
debe aprender a diseñar soluciones en el lenguaje que el cliente le
solicite y no en el lenguaje que el desarrollador escoja.
En próximas entradas voy a cargar información relacionada sobre
scripts y sistemas de información que he desarrollado y liberado al
público en general para compartir y propagar el conocimiento.