En los últimos años, n8n se ha
consolidado como una de las herramientas más potentes y flexibles
para la automatización de flujos de trabajo. Gracias a su naturaleza
open source, es posible instalarlo en un servidor propio y mantener
un control total sobre la información y la infraestructura.
En
este artículo aprenderás a configurar una instancia de n8n en tu
servidor utilizando Docker, incluyendo la personalización del
archivo .env con parámetros esenciales como base de datos, servidor
de correo y zona horaria.
🌐 Requisitos previos
Antes
de comenzar, asegúrate de contar con lo siguiente en tu servidor:
-
Docker y Docker Compose instalados.
- Un usuario con privilegios
de administrador.
- Acceso a un dominio o subdominio (opcional,
pero recomendado).
- Conocimientos básicos de Linux.
📂 Estructura de archivos
En
el directorio de tu proyecto, necesitarás al menos dos archivos:
1.
docker-compose.yml
2. .env
⚙️ Archivo
docker-compose.yml
Este archivo define los servicios
necesarios para levantar la instancia de n8n. A continuación, un
ejemplo básico:
El archivo .env es fundamental para definir
parámetros como la base de datos, el servidor de correo y la zona
horaria. Aquí tienes un ejemplo práctico:
# Ejemplo de clave
encriptación
N8N_ENCRYPTION_KEY=GeneraUnaClaveLargaYAleatoria
🔑 Recomendaciones importantes:
-
Usa contraseñas seguras tanto en la base de datos como en el
servidor de correo.
- Si tu servidor expone n8n a internet,
asegúrate de configurarlo detrás de un proxy reverso con SSL (por
ejemplo, Nginx + Certbot).
- Cambia la clave de encriptación
por una cadena única y segura.
▶️ Levantar la instancia
Con
ambos archivos listos, solo necesitas ejecutar:
docker-compose
up -d
Esto descargará la imagen de n8n, creará los
contenedores y montará el servicio en el puerto 5678.
Con esta
configuración, ya tendrás n8n funcionando en tu propio servidor con
Docker, completamente personalizado con tu base de datos, servidor de
correo y parámetros de seguridad.
La ventaja de usar
Docker es que puedes actualizar, escalar o migrar tu instancia
fácilmente, sin preocuparte por configuraciones manuales
complejas.
Ahora estás listo para comenzar a diseñar
flujos de trabajo automatizados que se adapten a tus necesidades.
En 2025, los desarrolladores continúan utilizando una variedad de
sistemas operativos, cada uno elegido según las necesidades específicas
de sus proyectos y preferencias personales.
A continuación, se destacan los sistemas operativos más empleados en la comunidad de desarrollo:
Windows
Desarrollado por Microsoft, Windows sigue siendo ampliamente
utilizado debido a su compatibilidad con una vasta gama de herramientas
de desarrollo y software empresarial. La interfaz familiar y el soporte
para aplicaciones heredadas lo hacen una opción popular, especialmente
en entornos corporativos.
macOS
El sistema operativo de Apple es preferido por desarrolladores que
trabajan en aplicaciones para iOS y macOS, gracias a su integración con
herramientas como Xcode. Además, su estabilidad y diseño atractivo lo
hacen popular entre profesionales creativos.
Linux
Linux, en sus diversas distribuciones como Ubuntu, Fedora y Debian,
es altamente valorado por su seguridad, estabilidad y flexibilidad. Es
especialmente popular entre desarrolladores de software de código
abierto y en entornos de servidores. Su naturaleza de código abierto
permite una personalización profunda, adaptándose a las necesidades
específicas de los desarrolladores.
Android e iOS
En el ámbito del desarrollo móvil, Android e iOS dominan el mercado.
Los desarrolladores eligen sus sistemas operativos de acuerdo con la
plataforma de destino de sus aplicaciones, utilizando Android Studio
para Android y Xcode para iOS.
La elección del sistema operativo por parte de los desarrolladores en
2025 sigue influenciada por factores como la compatibilidad con
herramientas específicas, la estabilidad, la seguridad y las
preferencias personales. La diversidad de opciones permite a los
profesionales seleccionar el entorno que mejor se adapte a sus
necesidades y objetivos de desarrollo.
Segun stackoverflow
Cada año exploran las herramientas y tecnologías que los desarrolladores utilizan actualmente y las que desean utilizar.
Este año, incluimos
nuevas preguntas sobre herramientas de tecnología integradas y opciones
de tecnología aprobadas por la comunidad y provenientes de la industria.
Para sorpresa de nadie Windows es el sistema operativo más popular
entre los desarrolladores, tanto para uso personal como profesional.
Windows para programadores en 2025
En 2025, Windows se consolida como una plataforma robusta y versátil
para desarrolladores, integrando tecnologías avanzadas que optimizan el
flujo de trabajo y potencian la productividad en diversas áreas de la
programación.
Integración de inteligencia artificial en dispositivos
Microsoft ha introducido mini PCs equipados con capacidades de
inteligencia artificial (IA), denominados Copilot Plus. Estos
dispositivos incorporan funciones como Recall, Click To Do y edición de
imágenes impulsada por IA en Windows 11. Fabricantes como Asus y Geekom
han presentado modelos que incluyen botones dedicados para acceder a
estas funcionalidades, facilitando tareas complejas y mejorando la
eficiencia en el desarrollo de software.
Avances en Windows Server 2025
La nueva versión de Windows Server ofrece mejoras significativas en
seguridad, rendimiento y flexibilidad. Entre las características
destacadas se encuentran la integración mejorada con GPU, virtualización
avanzada con Hyper-V y soporte para redes definidas por clústeres.
Estas innovaciones proporcionan a los desarrolladores un entorno más
robusto para la creación y gestión de aplicaciones empresariales.
Soporte ampliado para arquitecturas ARM64
Windows Server 2025 es el primer sistema operativo de servidor de
Microsoft en ofrecer soporte para la arquitectura ARM64, ampliando las
opciones de hardware disponibles para los desarrolladores y permitiendo
la creación de soluciones más eficientes y adaptadas a diversas
plataformas.
Actualizaciones automáticas y hotpatching
La implementación de actualizaciones automáticas a través de Windows
Update y la funcionalidad de hotpatching permiten a los desarrolladores
mantener sus sistemas actualizados sin interrupciones significativas,
mejorando la seguridad y estabilidad del entorno de desarrollo.
Optimización para inteligencia artificial y aprendizaje automático
Las mejoras en la integración de GPU y la virtualización avanzada
hacen de Windows una plataforma ideal para el desarrollo de aplicaciones
de inteligencia artificial y aprendizaje automático, ofreciendo el
rendimiento y la escalabilidad necesarios para manejar cargas de trabajo
intensivas en datos.
En resumen, Windows en 2025 proporciona a los desarrolladores un
ecosistema enriquecido con tecnologías de vanguardia, facilitando la
creación de soluciones innovadoras y adaptándose a las demandas
crecientes del sector tecnológico.
Linux para programadores en 2025
En 2025, Linux se consolida como una plataforma esencial para
programadores, ofreciendo una amplia variedad de distribuciones
adaptadas a diversas necesidades y preferencias. A continuación, se
destacan algunas de las distribuciones más recomendadas para
desarrolladores:
Ubuntu
Reconocida por su estabilidad y amplia comunidad de soporte, Ubuntu
es una opción popular entre programadores de todos los niveles. Su
compatibilidad con una vasta gama de herramientas de desarrollo y su
facilidad de uso la convierten en una elección sólida.
Fedora
Conocida por incorporar tecnologías de vanguardia, Fedora es
preferida por desarrolladores que buscan un entorno actualizado y
estable. Su enfoque en la innovación la hace adecuada para proyectos que
requieren las últimas herramientas y bibliotecas.
Arch Linux
Para aquellos que desean un control total sobre su entorno de
desarrollo, Arch Linux ofrece una experiencia minimalista y altamente
configurable. Requiere conocimientos avanzados, pero recompensa con un
sistema optimizado según las necesidades específicas del programador.
Debian
Conocida por su estabilidad y robustez, Debian es una distribución
ideal para desarrolladores que buscan un entorno confiable. Su amplia
colección de paquetes y su enfoque en la seguridad la hacen adecuada
para proyectos de larga duración.
La elección de la distribución adecuada dependerá de las necesidades
específicas del proyecto, el nivel de experiencia del desarrollador y
las preferencias personales en cuanto a entorno de trabajo. La
diversidad de opciones en el ecosistema Linux garantiza que cada
programador pueda encontrar la distribución que mejor se adapte a sus
requerimientos en 2025.
MacOs para programadores en 2025
En 2025, macOS se consolida como una plataforma robusta y versátil
para desarrolladores, ofreciendo herramientas avanzadas y un entorno
optimizado para diversas disciplinas de programación.
macOS 15 Sequoia: Innovaciones para desarrolladores
La introducción de macOS 15 Sequoia ha traído consigo mejoras
significativas que potencian la productividad y la eficiencia en el
desarrollo de software. Entre las novedades más destacadas se
encuentran:
Apple Intelligence: Integración de capacidades de
inteligencia artificial que facilitan tareas como la generación de
código, corrección de errores y optimización de procesos.
iPhone Mirroring: Permite a los desarrolladores
acceder y controlar aplicaciones móviles directamente desde el Mac,
simplificando el proceso de desarrollo y prueba de aplicaciones para
iOS.
Mejoras en Safari: Incorporación de herramientas
avanzadas para desarrolladores web, incluyendo un inspector de elementos
más potente y soporte ampliado para tecnologías web emergentes.
Nuevas herramientas y recursos para desarrolladores
Apple ha potenciado su ecosistema de desarrollo con la actualización
de Xcode y la introducción de nuevas API que amplían las posibilidades
de creación de aplicaciones. Las mejoras en Swift y la incorporación de
Swift Assist proporcionan un entorno más intuitivo y eficiente para la
codificación.
Hardware de alto rendimiento: MacBook Pro con chips M4
El lanzamiento de los nuevos MacBook Pro equipados con los chips M4,
M4 Pro y M4 Max ofrece a los desarrolladores un rendimiento excepcional.
Estos dispositivos están diseñados para manejar cargas de trabajo
intensivas, como compilación de código, renderizado y ejecución de
máquinas virtuales, mejorando significativamente la productividad.
Integración de Apple Intelligence en el ecosistema Mac
La llegada de Apple Intelligence a macOS proporciona herramientas de
escritura avanzadas, mejoras en Siri y capacidades de generación de
contenido mediante inteligencia artificial. Estas funcionalidades
asisten a los desarrolladores en la creación de documentación,
generación de código y otras tareas relacionadas con el desarrollo de
software.
Perspectivas futuras
Con estas actualizaciones, macOS se posiciona como una plataforma
líder para desarrolladores en 2025, ofreciendo un entorno integrado que
combina hardware de alto rendimiento, herramientas de desarrollo
avanzadas y capacidades de inteligencia artificial que facilitan y
optimizan el proceso de creación de software.
Android para programadores en 2025
En 2025, el desarrollo de aplicaciones para Android se encuentra en
una etapa de constante evolución, impulsada por avances tecnológicos y
tendencias emergentes que redefinen la forma en que los programadores
crean y optimizan sus aplicaciones.
Novedades en Android 16
La segunda vista previa para desarrolladores de Android 16, lanzada
en diciembre de 2024, introduce mejoras significativas que impactan
directamente en el proceso de desarrollo:
Nuevas API hápticas: Permiten una integración más precisa de respuestas táctiles, enriqueciendo la experiencia del usuario.
Optimización de JobScheduler: Mejora la ejecución de tareas en segundo plano, aumentando la eficiencia y el rendimiento de las aplicaciones.
Perfilado activado por el sistema: Facilita a los desarrolladores la identificación y resolución de problemas de rendimiento.
Funciones de seguridad avanzadas: Incluyen medidas para proteger la ubicación WiFi, reforzando la privacidad del usuario.
Optimización de tasas de refresco adaptativas: Mejora la fluidez visual, adaptándose dinámicamente a las necesidades de la aplicación.
Se espera que la versión final de Android 16 esté disponible entre
abril y junio de 2025, brindando a los desarrolladores un entorno más
robusto y seguro para la creación de aplicaciones.
Tendencias emergentes en el desarrollo de aplicaciones móviles
El panorama del desarrollo de aplicaciones móviles en 2025 está marcado por varias tendencias clave:
Edge Computing: Gana relevancia al permitir el
procesamiento de datos más cercano al usuario, reduciendo la latencia y
mejorando la eficiencia, especialmente en aplicaciones que requieren
respuestas en tiempo real.
Inteligencia Artificial y Automatización: La IA se
integra profundamente en las aplicaciones, ofreciendo personalización
avanzada y automatización de tareas, mejorando la experiencia del
usuario y optimizando procesos internos.
Sostenibilidad en el Diseño de Apps: Existe un
enfoque creciente en desarrollar aplicaciones que promuevan prácticas
sostenibles, optimizando el consumo de energía y recursos, alineándose
con la conciencia ambiental global.
Desarrollo Multiplataforma: Herramientas como
Flutter y React Native permiten a los desarrolladores crear aplicaciones
que funcionan en múltiples sistemas operativos, reduciendo costos y
tiempos de desarrollo, y alcanzando una audiencia más amplia.
Integración del Internet de las Cosas (IoT): Las
aplicaciones móviles se convierten en centros de control para
dispositivos conectados, ofreciendo a los usuarios la capacidad de
gestionar múltiples aspectos de su vida digital y física desde una sola
interfaz.
Preparación para dispositivos y tecnologías emergentes
Los desarrolladores deben adaptarse a innovaciones como los dispositivos plegables y la expansión de la conectividad 5G:
Optimización para dispositivos plegables: Requiere
interfaces adaptativas que ofrezcan experiencias consistentes sin
importar la configuración del dispositivo, aprovechando las pantallas
más grandes y las nuevas formas de interacción.
Aprovechamiento de la conectividad 5G: Permite el
desarrollo de aplicaciones más rápidas y con mayor capacidad de
respuesta, habilitando funcionalidades avanzadas como streaming de alta
calidad y experiencias de realidad aumentada en tiempo real.
Enfoque en la seguridad y privacidad
Con la creciente preocupación por la protección de datos, los
desarrolladores deben implementar medidas robustas para garantizar la
seguridad de la información del usuario, cumpliendo con regulaciones más
estrictas y respondiendo a una mayor conciencia pública sobre la
privacidad digital.
En resumen, el desarrollo de aplicaciones para Android en 2025 está
definido por la adopción de nuevas tecnologías y tendencias que buscan
ofrecer experiencias más eficientes, personalizadas y seguras,
adaptándose a un ecosistema móvil en constante transformación.
iOS para programadores en 2025
En 2025, el ecosistema de desarrollo para iOS ha experimentado
avances significativos, ofreciendo a los programadores herramientas y
funcionalidades que optimizan la creación de aplicaciones más
inteligentes y eficientes.
iOS 18: Innovaciones para desarrolladores
Con el lanzamiento de iOS 18, Apple ha introducido mejoras que impactan directamente en el proceso de desarrollo:
Apple Intelligence: Este conjunto de herramientas
de inteligencia artificial permite a los desarrolladores integrar
funcionalidades avanzadas en sus aplicaciones, como generación de
contenido y procesamiento de lenguaje natural.
Siri mejorado: La actualización de Siri, potenciada
por modelos de lenguaje avanzados, ofrece interacciones más naturales y
precisas, facilitando su integración en aplicaciones que requieren
comandos de voz.
Nuevas APIs: iOS 18 introduce APIs que permiten a
los desarrolladores acceder a funcionalidades avanzadas del sistema,
mejorando la personalización y el rendimiento de las aplicaciones.
Tendencias en el desarrollo de aplicaciones móviles
El panorama del desarrollo móvil en 2025 está marcado por tendencias que los desarrolladores de iOS deben considerar:
Inteligencia Artificial y Machine Learning: La
integración de IA y ML en las aplicaciones permite ofrecer experiencias
más personalizadas y eficientes, adaptándose a las necesidades
específicas de los usuarios.
Desarrollo No-Code y Low-Code: Estas plataformas
facilitan la creación de aplicaciones sin necesidad de una codificación
extensa, permitiendo a los desarrolladores centrarse en funcionalidades
más complejas y reduciendo los tiempos de desarrollo.
Edge Computing: El procesamiento de datos en el
dispositivo mejora la velocidad y la eficiencia de las aplicaciones,
reduciendo la dependencia de la nube y ofreciendo respuestas más rápidas
a los usuarios.
Actualizaciones en Xcode y Swift
Apple ha actualizado Xcode y el lenguaje de programación Swift,
proporcionando a los desarrolladores herramientas más potentes y
eficientes para la creación de aplicaciones:
Xcode 15: Incluye mejoras en el rendimiento del
compilador, nuevas herramientas de depuración y una integración más
profunda con Apple Intelligence, facilitando el desarrollo de
aplicaciones avanzadas.
Swift 6: Introduce características que simplifican
la sintaxis y mejoran la seguridad del código, permitiendo a los
desarrolladores escribir aplicaciones más robustas y mantenibles.
Perspectivas futuras
El desarrollo para iOS en 2025 se centra en la creación de
aplicaciones más inteligentes, eficientes y adaptadas a las necesidades
cambiantes de los usuarios. La integración de tecnologías emergentes y
la adopción de nuevas tendencias permiten a los desarrolladores ofrecer
experiencias más enriquecedoras y personalizadas en el ecosistema de
Apple.
El proyecto QEMU ha anunciado la disponibilidad de su versión 10.0, una actualización que introduce mejoras sustanciales en rendimiento, compatibilidad y soporte para diversas arquitecturas, consolidándose como una herramienta esencial en entornos de virtualización y emulación de sistemas.
Optimización en la Emulación x86 y Nuevos Modelos de CPU
QEMU 10.0 presenta una emulación más eficiente de instrucciones de cadenas en arquitecturas x86, lo que se traduce en un rendimiento mejorado en operaciones de memoria complejas.Además, se incorporan nuevos modelos de CPU, como Clearwater Forest y Sierra Forest v2, permitiendo la virtualización de sistemas que requieren procesadores Intel de última generación.
Mejora en la Gestión de I/O con Soporte Multiqueue en virtio-scsi
El dispositivo virtio-scsi ahora cuenta con soporte multiqueue completo, permitiendo que diferentes colas de un único controlador sean procesadas por distintos hilos de I/O.Esta funcionalidad mejora la escalabilidad y el rendimiento en operaciones de entrada/salida, especialmente en entornos con alta demanda de datos.
Avances en Aceleración Gráfica para Invitados macOS
Se introducen dos nuevos dispositivos gráficos: apple-gfx-pci y apple-gfx-mmio, diseñados para proporcionar aceleración gráfica en máquinas virtuales macOS.El primero está orientado a sistemas x86_64, mientras que el segundo se enfoca en entornos AArch64, mejorando significativamente la experiencia gráfica en entornos virtualizados de Apple.
Ampliación de Compatibilidad en Arquitecturas ARM y RISC-V
En la arquitectura ARM, se añade soporte para características como FEAT_AFP, FEAT_RPRES y FEAT_XS, así como la emulación de temporizadores físicos y virtuales Secure EL2.También se incorporan nuevas placas, como NPCM845 Evaluation e i.MX 8M Plus EVK.
Para RISC-V, se incluye soporte para CPUs como Tenstorrent Ascalon y Xiangshan Nanhu, además de extensiones ISA como svukte y ssstateen.Estas mejoras refuerzan el compromiso de QEMU con la compatibilidad y el soporte para arquitecturas emergentes.
Mejoras en Arquitecturas HPPA, s390x y LoongArch
En HPPA, se permite la emulación de hasta 256 GB de RAM en sistemas invitados de 64 bits, junto con mejoras en la emulación de dispositivos PCI específicos.La arquitectura s390x recibe soporte para virtio-mem y la opción de evitar la IOMMU para dispositivos PCI, mejorando el rendimiento . Por su parte, LoongArch incorpora funciones como extioi virtual y hotplug de CPU, ampliando sus capacidades en entornos virtualizados.
Integración de Rust y Mejoras en VFIO
QEMU 10.0 avanza en la integración de Rust para el desarrollo de modelos de dispositivos, aunque esta funcionalidad aún se considera experimental.Además, se implementan mejoras en VFIO, como soporte para migración multifd y compatibilidad con GPUs ATI antiguas, así como mejoras en la documentación y en el seguimiento de memoria sucia.
Conclusión
La versión 10.0 de QEMU representa un paso significativo en la evolución de este emulador y virtualizador de código abierto, ofreciendo mejoras clave en rendimiento, compatibilidad y soporte para múltiples arquitecturas.Estas actualizaciones refuerzan su posición como una herramienta indispensable para desarrolladores y profesionales que trabajan en entornos de virtualización avanzados.
Fedora continúa consolidando su posición como una distribución pionera en la adopción de tecnologías emergentes.En esta ocasión, se ha presentado una propuesta para Fedora 43 que busca eliminar los paquetes de GNOME sobre X11, apostando por una experiencia exclusiva en Wayland.
Desde hace varios años, el equipo de desarrollo de GNOME ha trabajado en la transición hacia Wayland, con el objetivo de ofrecer una arquitectura moderna, segura y eficiente.Con la llegada de GNOME 48, se han resuelto los principales obstáculos que impedían esta migración, y se espera que para GNOME 49 el soporte para X11 esté deshabilitado por defecto, con una eliminación completa prevista para GNOME 50.
En este contexto, Fedora propone adelantarse a estos cambios, eliminando los paquetes de GNOME sobre X11 en su versión 43.Esta decisión se basa en la falta de mantenimiento y pruebas en la sesión de GNOME sobre X11, así como en la presencia de errores críticos no resueltos.
Implicaciones para los Usuarios
La transición propuesta implica que los usuarios que actualicen a Fedora 43 serán migrados automáticamente a la sesión de GNOME en Wayland.El gestor de sesiones GDM ya no ofrecerá la opción de iniciar una sesión en X11.No obstante, las aplicaciones que dependen de X11 seguirán funcionando mediante XWayland, lo que garantiza la compatibilidad con la mayoría del software existente.
Para aquellos usuarios que requieran una experiencia nativa en X11, Fedora sugiere considerar entornos de escritorio alternativos como Cinnamon o MATE, junto con gestores de inicio como LightDM, que continúan ofreciendo soporte para X11.
Beneficios de la Transición
Adoptar Wayland como única opción para GNOME en Fedora 43 ofrece múltiples ventajas:
Mejora en la Seguridad: Wayland proporciona un modelo de seguridad más robusto al evitar que las aplicaciones interfieran entre sí.
Rendimiento Optimizado: Al eliminar capas de compatibilidad, se logra una experiencia de usuario más fluida y eficiente.
Alineación con el Desarrollo de GNOME: Esta decisión sincroniza a Fedora con la hoja de ruta de GNOME, facilitando futuras actualizaciones y mejoras.
Consideraciones Finales
La propuesta para Fedora 43 representa un paso significativo hacia la modernización del entorno de escritorio GNOME, alineándose con las tendencias actuales en el desarrollo de software de código abierto.Si bien la transición puede presentar desafíos para ciertos usuarios, las ventajas en términos de seguridad, rendimiento y mantenimiento justifican esta evolución.
Es recomendable que los usuarios evalúen sus necesidades específicas y consideren las opciones disponibles para garantizar una experiencia óptima en Fedora 43.
Si eres dev y te interesa el desarrollo de aplicaciones biométricas
con el SDK DigitalPersona, aquí te comparto unos enlaces que quizás
puedan ser de utilidad para tus proyectos:
En el mundo de la tecnología, los dispositivos USB, como las cámaras
web, han evolucionado rápidamente. Sin embargo, a veces necesitamos
conectar dispositivos más antiguos, lo cual puede presentar ciertos
desafíos, especialmente en sistemas Linux como Debian 12. Este artículo
te guiará a través del proceso de detección y configuración de
dispositivos USB antiguos, usando el ejemplo de una cámara web, y cómo
asegurarte de que funcione correctamente en tu sistema Debian 12.
1. Conectando el Dispositivo USB y Verificando su Detección
El primer paso es asegurarte de que Debian detecte el dispositivo USB
cuando lo conectas. Para ello, utilizaremos algunos comandos esenciales
que te ayudarán a saber si el dispositivo ha sido reconocido.
a) Usa el comando lsusb:
El comando lsusb te permitirá listar todos los dispositivos USB conectados al sistema. Abre la terminal y escribe:
lsusb
Esto mostrará una lista de todos los dispositivos USB conectados. Si
tu cámara web es reconocida, deberías ver algo que mencione el
fabricante o el tipo de dispositivo, por ejemplo:
Bus 001 Device 002: ID 046d:0825 Logitech, Inc. Webcam C270
Si no ves tu dispositivo en la lista, prueba cambiar de puerto USB o verificar el cable.
b) Verifica dispositivos de video (/dev/video):
Para cámaras web, el sistema suele asignar un dispositivo de video.
Usa el siguiente comando para verificar si tu cámara fue detectada como
un dispositivo de video:
ls /dev/video*
Si el dispositivo fue detectado correctamente, verás algo como /dev/video0. Si no aparece, puede ser un indicador de que el sistema no ha cargado el controlador correcto.
2. Instalando Herramientas para Video y Controladores de Cámaras
En la mayoría de los casos, las cámaras web modernas y antiguas funcionan con el subsistema V4L2 (Video for Linux 2). Si no tienes las herramientas necesarias instaladas, puedes hacerlo fácilmente:
a) Instalar V4L2 (Video for Linux 2):
Para asegurarte de que tu sistema pueda manejar correctamente los dispositivos de video, instala las utilidades de V4L2:
sudo apt install v4l-utils
Este paquete incluye herramientas útiles para controlar dispositivos
de video. Una vez instalado, puedes listar los dispositivos de video
detectados usando:
v4l2-ctl –list-devices
Si tu cámara web aparece en la lista, el sistema ya la ha detectado correctamente.
b) Instalar controladores para cámaras antiguas:
Algunas cámaras USB más antiguas pueden no ser compatibles con el controlador genérico de Linux, uvcvideo, que gestiona la mayoría de las cámaras modernas. Verifica si el módulo uvcvideo está cargado:
lsmod | grep uvcvideo
Si no aparece, puedes cargarlo manualmente:
sudo modprobe uvcvideo
Si tu cámara es muy antigua y no es compatible con uvcvideo,
podrías necesitar buscar controladores específicos para Linux.
Investiga el modelo de tu cámara y busca controladores o soluciones en
foros de la comunidad.
3. Solucionando Problemas de Detección
Si después de los pasos anteriores la cámara sigue sin ser reconocida, hay algunas cosas que puedes intentar:
a) Ver mensajes de error en el sistema (dmesg):
Cuando conectas un dispositivo USB, el kernel de Linux genera
mensajes sobre lo que está ocurriendo con el hardware. Puedes revisar
estos mensajes utilizando:
dmesg | grep -i usb
Esto mostrará cualquier mensaje relevante relacionado con
dispositivos USB. Si ves mensajes de error o advertencias, podrías tener
una pista sobre lo que está fallando.
b) Actualizar el sistema y controladores:
En algunas ocasiones, los problemas de compatibilidad se deben a
controladores o kernel desactualizados. Actualiza tu sistema para
asegurarte de que tienes las últimas versiones del software:
sudo apt update && sudo apt upgrade
4. Probar la Cámara con Software de Video
Si todo ha ido bien hasta este punto, deberías poder probar la cámara web. Una manera fácil de hacerlo es con el software Cheese, que está diseñado para tomar fotos y grabar video desde cámaras conectadas:
a) Instalar Cheese:
sudo apt install cheese
Luego de instalar, abre la aplicación Cheese desde el menú de aplicaciones o ejecuta:
cheese
Si Cheese detecta la cámara, deberías ver el video en pantalla. Si la
cámara no aparece, podrías necesitar seguir investigando los
controladores o probar con otro software, como VLC.
b) Usar VLC para probar el dispositivo de video:
Otra opción es probar el dispositivo de video con VLC. Abre VLC y
selecciona «Dispositivo de captura» desde el menú. O bien, puedes
ejecutarlo desde la terminal directamente:
vlc v4l2:///dev/video0
5. Conclusión
Conectar dispositivos USB antiguos, como cámaras web, a sistemas
modernos como Debian 12 puede ser un desafío, pero siguiendo estos pasos
es posible hacerlo funcionar. Verifica que el dispositivo esté
correctamente detectado usando herramientas como lsusb y v4l2-ctl,
asegúrate de que los controladores estén instalados y prueba el
funcionamiento con software de video como Cheese o VLC. Si el
dispositivo aún no es reconocido, considera buscar controladores
adicionales o soporte en línea para tu modelo específico de cámara.
¡Espero que esta guía te haya sido útil para revivir tu cámara web antigua en Debian 12!
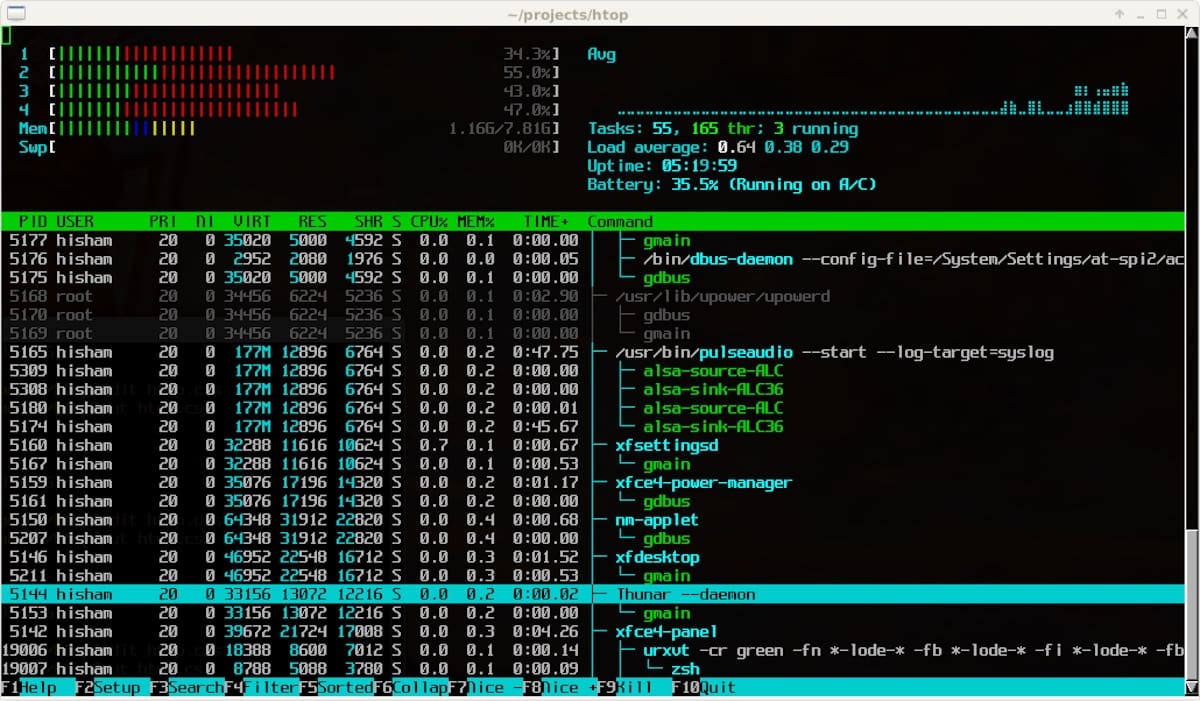
En el mundo de la administración de sistemas Linux, las herramientas
de monitoreo de recursos juegan un papel crucial para supervisar el
rendimiento del hardware y la eficiencia del sistema. Dos de las más
populares son btop y htop. Ambas
ofrecen funcionalidades avanzadas para ver el uso del CPU, la memoria y
los procesos activos, pero difieren en diseño, funcionalidad y enfoque. A
continuación, comparamos las ventajas y desventajas de cada una.
htop: El clásico visualizador de procesos
htop es una herramienta de monitoreo interactiva que reemplaza al comando básico top.
Se lanzó en 2004 y se convirtió rápidamente en una herramienta
preferida por su interfaz más accesible y sus opciones de
personalización. Aquí algunos puntos clave:
Pros de htop:
Interfaz amigable: htop mejora la experiencia de top al ofrecer una interfaz colorida y fácil de entender con gráficos para CPU y memoria.
Navegación interactiva: Puedes desplazarte fácilmente entre los procesos y aplicar filtros para buscar tareas específicas.
Acciones rápidas: Permite matar, renombrar o priorizar procesos directamente desde la interfaz, sin necesidad de comandos complicados.
Ligero y eficiente: Consume pocos recursos, lo que
lo hace ideal para sistemas con recursos limitados o para
administradores que buscan un monitor ligero.
Contras de htop:
Limitaciones en la personalización: Aunque htop
tiene varias opciones de configuración, carece de la flexibilidad que
otras herramientas modernas, como btop, ofrecen en términos de
visualización y uso de datos.
Soporte gráfico básico: Aunque su interfaz es clara, htop tiene menos opciones gráficas avanzadas comparado con herramientas más recientes.
btop: La evolución en la monitorización
btop es una herramienta más reciente basada en bashtop,
diseñada para ser visualmente atractiva y extremadamente funcional. Es
conocida por su interfaz gráfica avanzada y la posibilidad de usar el
ratón, algo inusual en este tipo de herramientas.
Pros de btop:
Interfaz avanzada: Con gráficos detallados y
personalizables, btop ofrece una experiencia visualmente mucho más rica
que htop. Incluye estadísticas detalladas del uso de CPU, memoria, red y
almacenamiento.
Soporte para ratón: A diferencia de htop, puedes
navegar completamente por la interfaz de btop usando el ratón, lo que
hace la interacción más sencilla y rápida.
Personalización completa: btop permite una
personalización profunda del aspecto y la disposición de los gráficos y
estadísticas, adaptándose a las necesidades del usuario.
Integración con otras herramientas: Ofrece información más detallada sobre la red y los discos, integrando de manera eficiente estas métricas en la interfaz.
Mejor gestión de recursos: Aunque btop es más
gráfico que htop, está bien optimizado, y su consumo de recursos es
competitivo, a pesar de la mayor cantidad de información que muestra.
Contras de btop:
Complejidad inicial: Su riqueza de funciones puede
resultar abrumadora para quienes buscan algo simple o están
acostumbrados a htop. La curva de aprendizaje es un poco más
pronunciada.
Mayor consumo de recursos: Aunque está optimizado,
su interfaz más compleja y sus gráficos avanzados pueden usar más
memoria que htop, lo que podría ser una limitante en sistemas con pocos
recursos.
¿Cuál elegir?
htop es ideal para administradores de sistemas que
buscan una herramienta ligera, rápida de usar y fácil de entender, con
un enfoque en procesos y rendimiento básico.
btop es más adecuado para aquellos que desean una
experiencia visual mejorada, mayor personalización y datos más completos
sobre la red, el almacenamiento y otros recursos del sistema.
En resumen, si estás buscando una herramienta tradicional, ligera y confiable, htop
sigue siendo una excelente opción. Sin embargo, si prefieres una
interfaz moderna, altamente gráfica y con mayor capacidad de
personalización, btop es una alternativa más avanzada y visualmente atractiva.
Conclusión
Ambas herramientas son poderosas a su manera. La elección entre btop y htop
dependerá de tus necesidades específicas y del entorno en el que estés
trabajando. Para usuarios más experimentados y entornos que requieren
una monitorización visual detallada, btop es una gran opción. Por otro
lado, si prefieres una solución clásica y minimalista, htop cumplirá
todas tus expectativas sin consumir demasiados recursos.
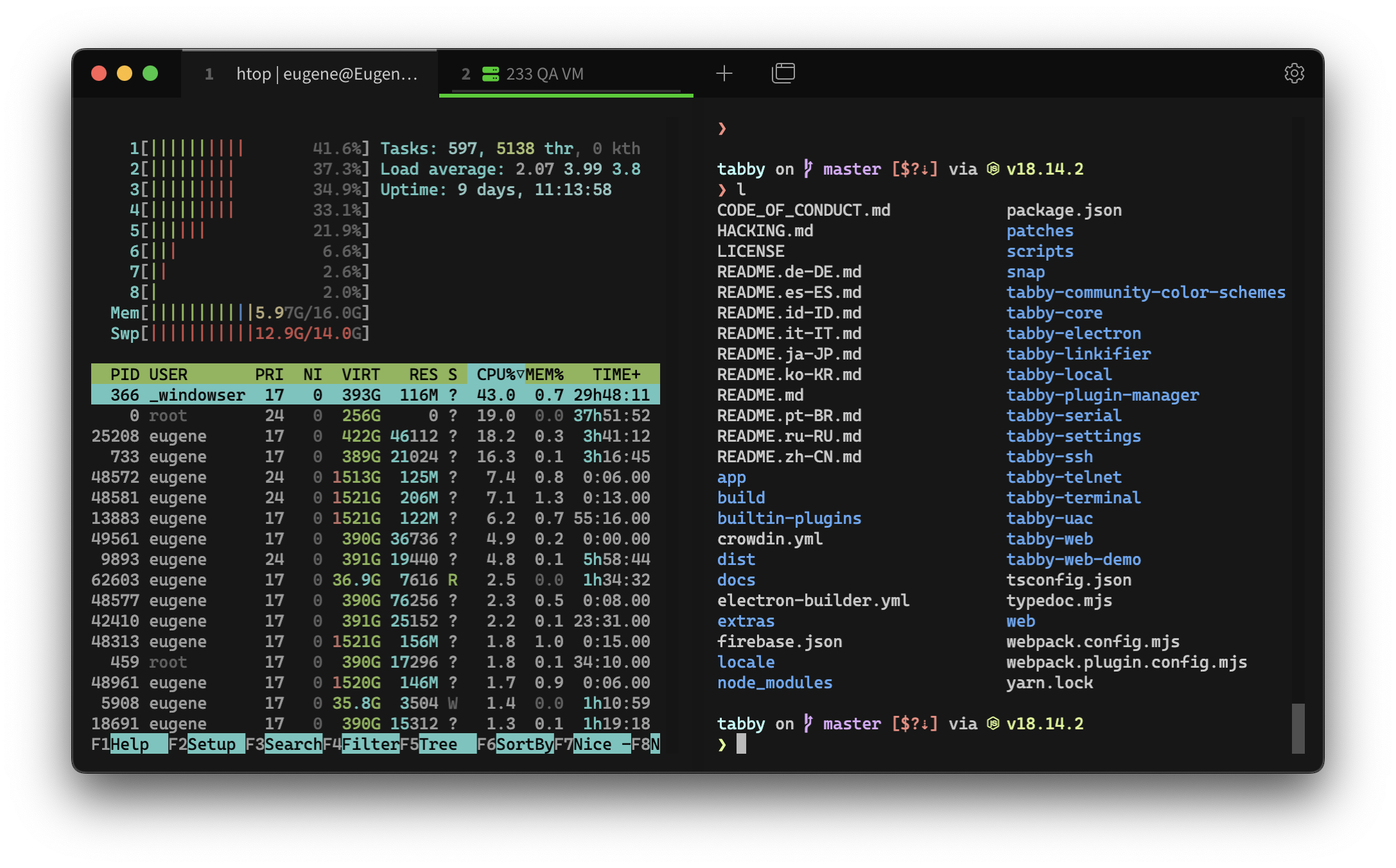
En el mundo del desarrollo, las terminales son herramientas
imprescindibles, pero no todas ofrecen la flexibilidad y personalización
que los desarrolladores modernos requieren. Tabby es
una terminal de código abierto que ha ganado popularidad por ser
altamente personalizable, multiplataforma y fácil de usar. En este
artículo, exploraremos qué es Tabby, sus principales características, y
por qué es una excelente opción para desarrolladores que buscan una
experiencia de terminal avanzada.
¿Qué es Tabby?
Tabby es una terminal moderna y multiplataforma que está disponible para Windows, macOS y Linux.
Su principal atractivo radica en su capacidad de personalización y su
diseño amigable, que combina una interfaz visual atractiva con
funcionalidades avanzadas. Al ser de código abierto, Tabby ofrece una
plataforma transparente y flexible para aquellos que quieran adaptar su
terminal a sus necesidades específicas.
El proyecto fue diseñado con la idea de mejorar la experiencia del
usuario, permitiendo a los desarrolladores trabajar de manera más
eficiente y productiva. A diferencia de muchas terminales clásicas que
pueden ser intimidantes para los nuevos usuarios, Tabby ofrece una
interfaz intuitiva y rica en características.
Características Clave de Tabby
Multiplataforma: Una de las principales ventajas de Tabby es que está disponible para todos los sistemas operativos principales: Windows, macOS y Linux. Esto la convierte en una opción ideal para desarrolladores que necesitan trabajar en varios entornos sin perder consistencia.
Altamente Personalizable: Tabby permite a los
usuarios ajustar su entorno de terminal con temas, atajos de teclado
personalizados, y la posibilidad de dividir ventanas. Los
desarrolladores pueden personalizar cada aspecto visual de la terminal,
desde los colores hasta la disposición de las pestañas y paneles.
Soporte para SSH y Serial: Tabby incluye soporte integrado para conexiones SSH
y seriales, lo que la hace ideal para la administración remota de
servidores o dispositivos. Esto elimina la necesidad de instalar
herramientas adicionales o abrir otras ventanas para estas tareas.
Interfaz de Pestañas y Paneles: Tabby permite abrir
varias pestañas y dividir la ventana en paneles, lo que es perfecto
para multitareas. Cada pestaña puede ejecutar diferentes sesiones o
comandos, permitiendo una mayor eficiencia al trabajar con múltiples
proyectos o entornos de desarrollo al mismo tiempo.
Extensiones: Al ser una terminal moderna, Tabby soporta la instalación de extensiones
que agregan más funcionalidades. Esto incluye temas adicionales,
soporte para más protocolos y funcionalidades especializadas, según las
necesidades del usuario.
Integración con SSH y Múltiples Shells: Además de su personalización, Tabby permite integrarse fácilmente con shells como Bash, Zsh, PowerShell, y más. También permite conectarse a servidores remotos utilizando SSH, lo cual es fundamental para administradores de sistemas y desarrolladores que gestionan servidores a distancia.
Usos y Aplicaciones de Tabby
Tabby es una excelente opción para diversos tipos de usuarios, desde
desarrolladores de software hasta administradores de sistemas. Aquí
algunos escenarios donde destaca su utilidad:
Desarrollo de Software: Los desarrolladores que
trabajan en proyectos multiplataforma o colaboran con equipos que usan
diferentes sistemas operativos encontrarán en Tabby una herramienta
unificadora. Al poder personalizar la terminal para cada proyecto o
lenguaje, Tabby facilita el trabajo en diferentes entornos sin tener que
cambiar de herramienta.
Administración de Sistemas: Para los administradores que gestionan servidores remotos, el soporte integrado para SSH
y la posibilidad de dividir la pantalla en varias sesiones simultáneas
permite monitorear y administrar múltiples sistemas a la vez.
Usuarios Avanzados: Los usuarios avanzados que
buscan maximizar la eficiencia en su flujo de trabajo disfrutarán de la
capacidad de Tabby de manejar scripts complejos, automatización de
tareas, y soporte para múltiples sesiones.
Comparación con Otras Terminales
En comparación con otras terminales populares como Hyper o Terminator,
Tabby destaca por su equilibrio entre una interfaz amigable y sus
funcionalidades avanzadas. Si bien otras terminales pueden ofrecer un
mayor enfoque en diseño o rendimiento en áreas específicas, Tabby brilla
por ser una opción sólida, equilibrada y con un amplio abanico de
personalización.
Conclusión
Tabby se ha consolidado como una excelente opción
para desarrolladores y administradores de sistemas que buscan una
terminal moderna, potente y personalizable. Su compatibilidad con
múltiples sistemas operativos, junto con su soporte para SSH y
extensiones, la convierte en una herramienta versátil que puede
adaptarse a casi cualquier flujo de trabajo. Ya sea que estés buscando
una terminal que se vea bien o que puedas modificar según tus
necesidades, Tabby ofrece una experiencia completa y eficiente.
Si eres un desarrollador o administrador de sistemas que busca una terminal poderosa, definitivamente vale la pena probar Tabby. Puedes descargarla directamente desde su sitio web aquí.
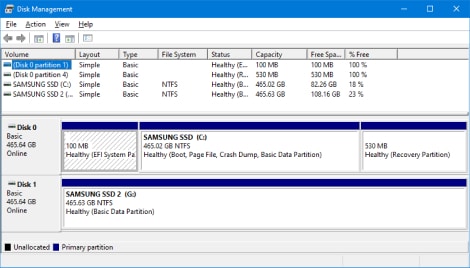
MBR vs. GPT, ¿cuál elegir? Puede que te preguntes lo mismo cuando
configures un Sistema Operativo en tu PC por primera vez. La selección
del esquema de particiones depende totalmente del tipo de Sistema
Operativo y del estado del hardware de tu equipo.
¿Cuál es la diferencia entre la partición MBR y GPT?
Aquí tratamos de responder a esa pregunta, a la vez que ofrecemos una
reseña que describe las características de ambos. Master Boot Record
(MBR) y Tabla de partición GUID (GPT) son dos tipos de esquemas de
partición para los discos duros, mientras que el segundo es más
avanzado.
Aunque estos dos tienen la misma función, cada uno tiene su propia
estructura de arranque, velocidad, capacidad, flexibilidad y requisitos.
Este artículo ofrece una comprensión más amplia de MBR vs. GPT y los pros y los contras de los métodos de inicialización, conversión y recuperación de MBR/GPT.
MBR vs. GPT: ¿Cuál es la diferencia?
GPT, abreviatura de GUID Partition Table (tabla de particiones) es el
nuevo estándar para la disposición de la tabla de particiones en un
disco duro físico. El MBR, abreviatura de Master Boot Record, es el
estándar más antiguo con la misma funcionalidad. Al particionar un disco
duro o utilizar una herramienta de partición de disco, puedes elegir
uno de estos dos métodos diferentes para la partición.
En comparación, el MBR es más antiguo que el GPT. El MBR funciona
mejor con los sistemas anteriores; en cuanto al GPT, es más compatible
con los sistemas más avanzados y nuevos.
La ventaja de GPT es el enorme tamaño de la partición, el número de particiones y la capacidad de recuperación.
Además, las computadoras que funcionan con UEFI sólo pueden soportar
GPT. Por no mencionar que Microsoft ha confirmado recientemente que el
sistema Windows 11 sólo será compatible con GPT y UEFI. Por tanto, el
disco GPT es uno de los elementos esenciales de Windows 11.
Aspectos más ventajosos de la GPT:
Tanto el MBR como el GPT pueden ser primarios o dinámicos. Sin
embargo, un disco GPT ofrece más capacidad, compatibilidad con
dispositivos modernos y mejor rendimiento. Estas son algunas de las
ventajas de GPT en comparación con MBR:
MBR (Registro de arranque maestro)
GTP (Tabla de Partición GUID)
Capacidad máxima de la partición
2 TB
9,4 ZB (cada ZB es 1.000 millones de TB)
Número máximo de particiones
hasta 4 particiones primarias (o tres particiones primarias, una partición extendida y unidades lógicas ilimitadas)
128 particiones primarias
Soporte de la Interfaz del Firmware
BIOS
UEFI
Compatibilidad del Sistema Operativo
Windows 7 e incluso sistemas más antiguos como Windows 95/98, Windows XP 32 bits, Windows 2000, Windows 2003 32 bits
Sistemas más nuevos como Windows 8, 8.1 de 64 bits, 10, 11.
Velocidad
Más lento
Más rápido
Tecnología más avanzada
Funciona con tecnología más avanzada
Funciona con tecnología y hardware menos avanzados
Capacidad de MBR vs. GPT: MBR sólo puede manejar 2
TB de espacio en el disco duro, mientras que GPT puede soportar discos
de más de 2 TB (ayuda a los volúmenes de hasta 18 exabytes de tamaño).
Particiones MBR vs. GPT: El estilo de partición de
disco MBR admite volúmenes de hasta 2 TB y cuatro particiones primarias
por disco (o tres particiones primarias, una partición extendida y
unidades lógicas ilimitadas). Pero la GPT no tiene límite de
particiones. Con GPT, los sistemas operativos Windows pueden tener hasta
128 particiones en una unidad GPT sin necesidad de crear una partición
extendida.
Recuperación MBR vs. GPT: Los discos con
particiones GPT tienen un primario y una copia de seguridad redundantes.
GPT mantiene los datos en varias áreas de la unidad una copia como
copia de seguridad secundaria Tabla GPT para la recuperación. Al mismo
tiempo, la desventaja del MBR es que almacena los datos en un solo
lugar, sin hacer copias de seguridad, lo que aumenta la posibilidad de
que se corrompan y de que el sistema falle.
Confiabilidad de MBR vs. GPT: El disco GPT
proporciona más fiabilidad gracias a la replicación y a la protección de
la tabla de particiones mediante la comprobación cíclica de redundancia
(CRC). A diferencia de los discos con partición MBR, los datos críticos
para el funcionamiento de la plataforma se encuentran en las
particiones en lugar de en los sectores no particionados u ocultos.
Tecnología y compatibilidad MBR vs. GPT: GPT puede utilizar tecnologías de dispositivos más avanzadas, mientras que MBR es para sistemas menos evolucionados.
Interfaz MBR vs. GPT: Normalmente, MBR y BIOS (MBR +
BIOS) y GPT y UEFI (GPT + UEFI) funcionan juntos. Este emparejamiento
es obligatorio para algunos sistemas operativos (por ejemplo, Windows),
mientras que es opcional para otros (por ejemplo, Linux).
Velocidad MBR vs. GPT: Por último, los procesos de arranque GPT y UEFI suelen ser más rápidos que los GPT.
MBR vs. GPT: ¿Cuál es mejor para tus necesidades?
Simplemente, la GPT es la mejor opción en muchos aspectos. Aunque el
mundo avanza hacia tecnologías más avanzadas, la GPT, con la última
compatibilidad tecnológica, supera al MBR. Si tu disco es de más de 2
TB, o si has decidido configurar un sistema operativo más reciente
como Windows 11, Definitivamente, elige el GPT.
Con una segunda copia de seguridad y una mejor administración de las
particiones, esta partición es más confiable y resistente a la
corrupción.
Tener un arranque rápido es otra ventaja de la GPT. Los SSD funcionan
de forma diferente a los HDD y son capaces de arrancar rápidamente.
Aunque tanto GPT como MBR funcionan bien, para tener un arranque rápido
de Windows, GPT es la mejor opción una vez más. Y porque requieres
una Sistema basado en UEFIm para un arranque más rápido, y UEFI sólo
funciona con el particionamiento GPT. Así que, una vez más, GPT parece
la opción más lógica cuando se trata de MBR o GPT para SSD.
Dicho esto, todavía hay ocasiones en las que no tienes más remedio
que optar por un MBR. Como si tuvieras un sistema operativo antiguo. O
cuando el hardware de tu vieja computadora no puede ejecutar una versión
más reciente de Windows. Sin embargo, hoy en día, los usuarios
prefieren trabajar con sistemas de alta calidad, ya que los SSD son más
compatibles con el último Windows. Así que, al final, todo depende de
tus preferencias, de la antigüedad de tu hardware y de que trabajes con
qué tipo de sistema operativo.
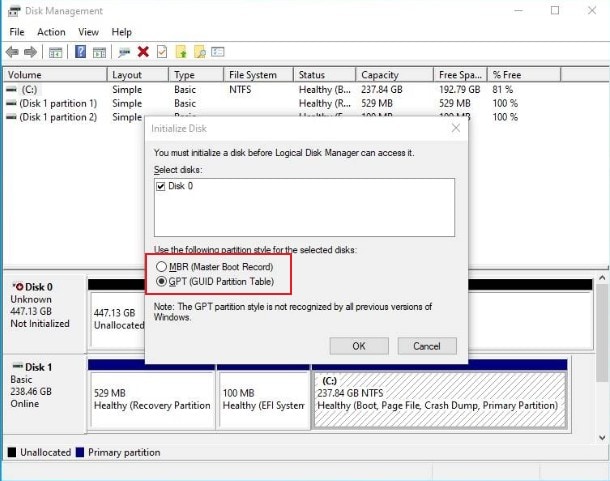
MBR vs. GPT: Cómo inicializar tu disco a MBR/GPT
Inicializar un MBR o GPT para SSD o HDD es un proceso sencillo que se
puede administrar con la «Administración de discos» de Windows y el
software disponible. Los pasos para inicializar el MBR/GPT con la
Administración de discos son los siguientes:
Paso 1: Pulsa sobre el acceso directo Windows+R para abrir «Ejecutar.»
Paso 2: Tipo “msc” para iniciar la gestión de discos.
Paso 3: A continuación, se te pedirá que inicialices el disco duro recién añadido. Entonces, puedes elegir entre MBR o GPT.
Cómo convertir GPT a MBR o MBR a GPT
Para convertir MBR en GPT o GPT en MBR, hay varias opciones
disponibles. Puedes conocer la guía de conversión completa haciendo clic
en los siguientes enlaces:
Consejos adicionales: Cómo recuperar datos de una partición MBR o GPT perdida
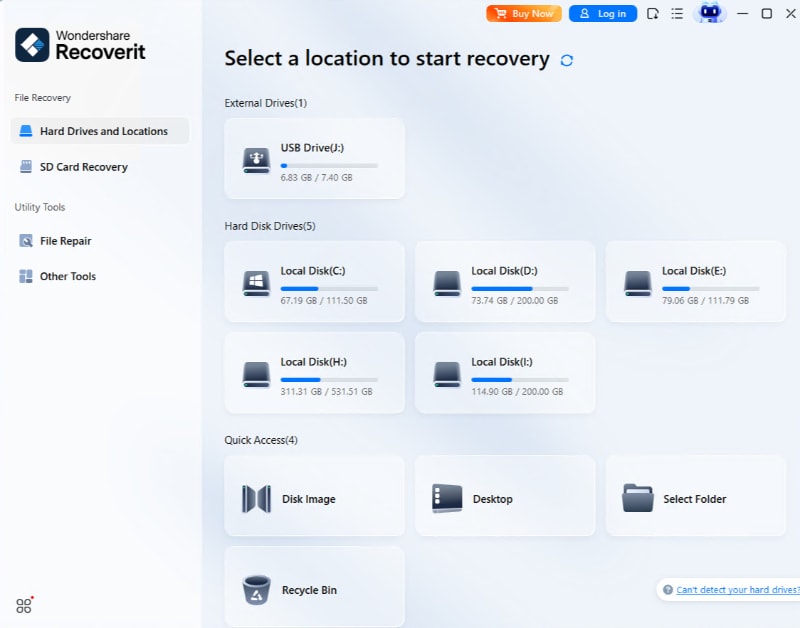
Wondershare Recoverit es uno de los programas más fiables disponibles
para recuperar particiones GPT y MBR en caso de pérdida de datos o de
diversos problemas relacionados. Puedes recuperar tus datos importantes
con este software profesional de recuperación de particiones en tres
sencillos pasos (Selecciona la partición perdida > Escanear > Recuperar).
Es muy importante colocar los valores de los atributos entre comillas
dobles. En caso de no colocar las comillas dobles, el procesador le
indicará que hubo un error.
ESTRUCTURA DE WEBREPORT-ML
Un reporte escrito en WEBREPORT-ML comienza y termina con la marca reporte, indicando que se trata de un reporte a realizar en el lenguaje.
<reporte>
Cuerpo del documento
</reporte>
Dentro del elemento reporte se encentran varios elementos primarios, tales como:
descripcion
salida
conexion
consulta
titulo
cabecera
detalles
pie-de-pagina
Ejemplo:
<?xml version=»1.0″ encoding =»iso-8859-1″?>
<reporte>
<conexion/>
<consulta>
Contenido de la consulta SQL
</consulta>
<margenes />
<salida/>
<titulo>
Reporte de Productos
</titulo>
<descripcion>
Contenido de la descripcion
</descripcion>
<cabecera>
<fila>
<campo> </campo>
</fila>
</cabecera>
<detalles>
<fila>
<campo/>
</fila>
</detalles>
<pie-de-pagina>
<fila>
<campo> </campo>
</fila>
</pie-de-pagina>
</reporte>
DESCRIPCIÓN DE LOS ELEMENTOS DEL LENGUAJE REPORT-ML
Elemento descripcion
El elemento descripcion se utiliza para colocar una información descriptiva acerca de los que se trata el reporte. Ejemplo:
<descripcion>
Este es un reporte para los empleados de la compañía
</descripcion>
Elemento margenes
El elemento margenes se utiliza para especificar cada uno de los márgenes para el documento del reporte y consta de los siguientes atributos:
Atributo margen-superior
Atributo margen-inferior
Atributo margen-izquierdo
Atributo margen-derecho
Elemento salida
El elemento salida se utiliza para especificar el formato en
el que se desea que se muestre el reporte, así como la ruta en donde se
guardará el reporte. Contiene los siguientes atributos:
Atributo formato
Atributo archivo
*Atributo formato
El atributo formato especifica el formato en el que se desea que se imprima el reporte. Los tipos de formatos disponibles en WEBREPORT-ML son:
Html
PDF
DocBook
*Atributo archivo
El atributo archivo especifica la ruta en donde se desea
guardar el reporte. Es importante que el usuario especifique una ruta
en donde se guardará su reporte para que al momento de terminar de
exportar los datos al formato requerido, sabrá que el reporte se alojará
precisamente en el lugar que él indicó.
Elemento conexion
El elemento conexion se utiliza para especificar los esquemas de conexión con la base de datos. Contiene los siguientes atributos:
*Atributo conector
El atributo conector especifica el motor de la base de datos a utilizar.
Ejemplo:
conector=»sun.jdbc.odbc.JdbcOdbcDriver»
*Atributo url
El atributo url la ruta de la base de datos de la siguiente manera:
jdbc:odbc:Base_de_Datos
Elemento consulta
El elemento consulta especifica el contenido de la consulta SQLque se va a utilizar para generar nuestro reporte.
Ejemplo:
<consulta>
select * from tabla
</consulta>
Elemento titulo
El elemento titulo se utiliza para el título del reporte.
Elemento cabecera
El elemento cabecera se utiliza para los títulos de cada campo del reporte. Contiene un elemento anidado fila el cual hace referencia a las filas deseadas por el usuario; ésta a su vez contiene un elemento anidado campo, que especifica el número de campos (columnas) que el usuario desea para esa fila.
Ejemplo:
<cabecera>
<fila>
<campo tipo=”texto”>
Nombre
</campo>
<campo tipo=”texto”>
Apellido
</campo>
</fila>
</cabecera>
Para el ejemplo anterior se mostrará, en una misma fila, varios
campos con los títulos para el reporte y quedaría de la siguiente forma:
Nombre
Apellido
Elemento detalles
El elemento detalles constituye uno de los elemento más
importantes del reporte, pues es ahí en donde se especifican cada uno de
los campos de la base de datos que se mostraran en el reporte, así
como también se realizan las fórmulas que se desean hacer para el
reporte. Las fórmulas deben codificarse en el lenguaje Java Script.
Existen dos tipos de campos diferentes a los anteriormente descritos,
que se utilizan en el detalle:
El tipo de campo bd
El tipo de campo formula
El tipo de campo bd, se utiliza
para especificar cada uno de los campos de la base de datos que el
usuario desea mostrar en el reporte. Para este tipo de campo, existe un
atributo llamado nombre, el cual especifica
el nombre del campo de la base de datos a extraer para el reporte. Cada
vez que el usuario especifique el tipo de campo bddebe especificar en el atributo nombre el nombre del campo de la base de datos.
Ejemplo:
<detalles>
<fila>
<campo tipo=”bd” nombre=”cedula”/>
<campo tipo=”bd” nombre=”nombre”/>
<campo tipo=”bd” nombre=”apellido”/>
</fila>
</detalles>
El tipo de campo formula,se utiliza para las distintas fórmulas que se desean hacer para el reporte.
Ejemplo:
<detalles>
<fila>
<campo tipo=”formula”>
value = parseInt(query.get(«CANTIDAD»)) * parseInt(query.get(«PRECIO»));
</campo>
</fila>
</detalles>
*Atributo formato
El atributo formato especifica el formato numérico a utilizarse. Este atributo hace parte del elemento anidado campo y se utiliza en caso de que se utilicen números y se les quiera aplicar algún tipo de formato.
Para el ejemplo anterior, se mostrarán todos los registros del campo Valor, correspondiente
al valor unitario de X producto y se le aplica el tipo de formato
$#.##0,00 así como el estilo de letra negrita. El resultado de uno de
los registros del campo valor, quedaría de la siguiente forma: $ 2,052,000.00
Elemento pie-de-pagina
El elemento pie-de-pagina se utiliza para colocar algún
contenido al final del reporte, como funciones para hallar el total de
un determinado campo de la base de datos, ó el gran total de algún total
hallado por medio de las fórmulas descritas en el detalles. Contiene un
elemento anidado fila el cual hace referencia a las filas deseadas por el usuario; ésta a su vez contiene un elemento anidado campo, que especifica el número de campos (columnas) que el usuario desea para esa fila.
Los tipos de campo utilizados en el pie-de-pagina son:
text
total
El campo total se utiliza única y exclusivamente en el
elemento pie-de-pagina. Este tipo de campo especifica la función a
llevar a cabo para hallar el total de un determinado campo de la base de
datos ó para hallar un resultado total de cada uno de los resultados
hallados en la fórmula escrita en el detalle.
También existe un atributo que va de la mano con el tipo de campo total y es el atributo funcion, el cual se explica a continuación.
*Atributo funcion
El atributo funcion especifica la función a utilizarse en el pie-de-pagina y depende del tipo de campo total. Los tipos de funciones disponibles para la el atributo funcion del pie-de-pagina son las siguientes:
Si el usuario va a utilizar en el reporte caracteres propios del
alfabeto español, tales como la letra ñ, tildes, etc, deberá incluir el
siguiente atributo al principio de la creación del reporte:
Para la instalar WEBREPORT-ML, el usuario deberá copiar la carpeta reportml que se encuentra el CD de instalación en el directorio Coligo Fuente, al disco duro y después crear un nuevo Context en el servidor de Apache TOMCAT, el alias debe ser /reportml y el documento base debe ser c:/reportml.
Para desinstalarlo, solo se elimina el Context del servidor y se borra el directorio de la raíz de C: .
Cabe recordar que dentro del directorio reportml se encuentra el directorio waren el cual se encuentra el archivo WebReport.war. Para instalar este archivo, hay dos opciones:
OPCION 1:
1) Copiar el fichero war a TOMCAT / webapps
2) Arrancar el servidor
3) La instalación es automática y crea un nuevo directorio con los contenidos del war.
OPCION 2:
1) Crear la aplicación Web descomprimida en webapps siguiendo el formato estándar.
2) Añadir en TOMCAT / conf / server.xml un nuevo contexto que apunte a nuestro directorio:
NOTA: En su momento este proyecto fue diseñado y
desarrollado bajo windows, sin embargo, puede funcionar con sistemas
operativos linux y macOs. Puedes acceder a todo el proyecto a través de
su repositorio oficial en github: https://github.com/rrcyber/WebReportML/
Los discos duros modernos pueden almacenar grandes cantidades de información. Para utilizar eficazmente todo este espacio, puedes particionar las unidades de disco en áreas de almacenamiento separadas. Estas áreas de almacenamiento separadas le permiten organizar sus datos, mejorar el rendimiento del sistema e instalar y utilizar muchos sistemas operativos.
Moviendo espacio entre particiones
Cómo administrar particiones con GParted
Gracias a las capturas de pantalla que te ayudarán a utilizar eficazmente el disco duro. Comenzarás con tareas sencillas que te ayudarán a identificar unidades y particiones. A continuación, avanza hacia tareas que cubren los aspectos básicos de cómo aumentar, reducir, mover y copiar particiones sin pérdida de datos. Terminará con tareas avanzadas que utilizan los conceptos básicos para prepararse para nuevos sistemas operativos, migrar espacio entre particiones y compartir datos entre Windows, Linux y Mac OS X.
Siguiendo las tareas, desde las más básicas hasta las más avanzadas, este tutorial te proporcionará el conocimiento y las herramientas para Gestionar particiones con GParted.
Mover espacio entre particiones
Puede ser frustrante quedarse sin espacio libre en una partición (por ejemplo, C:) cuando otra partición (por ejemplo, D:) tiene mucho. En esta receta cubrimos los pasos para migrar espacio libre de una partición a otra.
Preparación
Antes de realizar esta tarea, te recomendamos encarecidamente que hagas una copia de seguridad de tus datos. Esta tarea implica mover el inicio del límite de una partición, lo cual es una actividad de alto riesgo.
Cómo hacerlo...
Selecciona la partición con mucho espacio libre.
Disposición original del disco con una partición primaria completa a la izquierda seguida de una partición extendida que contiene una partición lógica con espacio libre.
Elige la opción de menú Partición | Redimensionar/Mover y aparecerá una ventana Redimensionar/Mover.
Haz clic en la parte izquierda de la partición y arrástrela hacia la derecha para que el espacio libre se reduzca a la mitad.
Ventana Redimensionar/Mover con el espacio no asignado a la izquierda seguido de la partición comprimida
Haz clic en Redimensionar/Mover para poner en cola la operación.
Pulsa Aceptar para aceptar la advertencia de mover partición.
Ventana de advertencia indicando que mover una partición puede hacer que el sistema operativo no arranque
Selecciona la partición extendida.
Disposición del disco mostrando una partición primaria completa seguida de una partición extendida que contiene espacio libre a la izquierda de una partición lógica
Elige la opción de menú Partición | Redimensionar/Mover y se mostrará una ventana Redimensionar/Mover.
Haz clic en el lado izquierdo de la partición y arrástrela hacia la derecha para que no quede espacio entre el límite exterior de la partición extendida y el límite interior de la partición lógica.
Ventana Redimensionar/Mover con espacio libre a la izquierda de la partición extendida y la partición lógica encajando perfectamente dentro de la partición extendida.
Haz clic en Redimensionar/Mover para poner en cola la operación.
Selecciona la partición que necesita más espacio libre:
Disposición del disco con una partición primaria completa a la izquierda, seguida de espacio sin asignar seguido de una partición extendida que contiene totalmente una partición lógica
Elige la opción de menú Partición | Redimensionar/Mover y se mostrará una ventana Redimensionar/Mover.
Haz clic en el lado derecho de la partición y arrástrela lo más a la derecha posible:
Ventana Redimensionar/Mover con la partición ocupando todo el espacio
Haz clic en Redimensionar/Mover para poner en cola la operación:
Disposición del disco con una partición primaria que ya no está llena a la izquierda, seguida de una cantidad muy pequeña de espacio sin asignar seguida de una partición extendida que contiene completamente una partición lógica
Observa el espacio sin asignar entre sda1 y sda2. Este espacio, que puede ser de hasta 8 MiB, ocurre debido a tener particiones alineadas por cilindros y por MiB en el mismo dispositivo de disco. En este ejemplo, la partición sda1 se creó con alineación de cilindros para demostrar este hueco potencial.
Elige la opción de menú Editar | Aplicar todas las operaciones para aplicar las operaciones en cola, al disco.
Haz clic en Aplicar para aplicar las operaciones al disco.
Aplicando
Cómo funciona..
Para añadir espacio a una partición, debe haber espacio sin asignar inmediatamente adyacente a la partición. Para liberar este espacio, utilizamos muchas de las recetas tratadas anteriormente.
En primer lugar, hicimos que el espacio no asignado estuviera disponible reduciendo la partición lógica en la que había espacio libre. Como el espacio libre procedía de una partición lógica dentro de una partición extendida, y necesitábamos añadir el espacio a una partición primaria, tuvimos que editar tres particiones para lograr el objetivo deseado.
Aún hay más...
Como se mencionó en recetas anteriores, si redimensiona o mueve una partición que contiene un sistema de archivos NTFS, debe reiniciar Windows dos veces para permitir que Windows realice comprobaciones de consistencia del sistema de archivos.
Aumentar o mover una partición
Para crecer o mover una partición, debe haber espacio sin asignar disponible adyacente a la partición:
Cuando se amplía una partición lógica, el espacio no asignado debe estar dentro de la partición extendida.
Cuando se amplía una partición primaria, el espacio no asignado no debe estar dentro de la partición extendida.
Puede mover el espacio no asignado dentro o fuera de una partición extendida redimensionando los límites de la partición extendida.