Introducción: Uso de bibliotecas nativas en Java
Una librería nativa es una librería que contiene código compilado para una arquitectura (nativa) específica. Hay ciertos escenarios, como las integraciones hardware-software y las optimizaciones de procesos, en los que el uso de bibliotecas escritas para diferentes plataformas puede ser muy útil o incluso necesario. Para ello, Java ofrece la Interfaz Nativa Java (JNI), que permite al código Java que se ejecuta dentro de una Máquina Virtual Java (JVM) interoperar con aplicaciones y bibliotecas escritas en otros lenguajes de programación, como C, C++ y ensamblador. La JNI permite al código Java llamar y ser llamado por aplicaciones y bibliotecas nativas escritas en otros lenguajes y permite a los programadores escribir métodos nativos para manejar situaciones en las que una aplicación no puede escribirse completamente en Java.
Los formatos habituales de las bibliotecas nativas son los archivos .dll en Windows, .so en Linux y .dylib en plataformas macOS. El lenguaje convencional para cargar estas bibliotecas en Java se presenta en el siguiente ejemplo de código.
package rollbar;
public class ClassWithNativeMethod {
static {
System.loadLibrary("someLibFile");
}
native void someNativeMethod(String arg);
/*...*/
}Java carga las bibliotecas nativas en tiempo de ejecución invocando el método System.load() o System.loadLibrary(). La principal diferencia entre ambos es que el último no requiere que se especifique la ruta absoluta y la extensión de archivo de la biblioteca, sino que se basa en la propiedad del sistema java.library.path. Para acceder a los métodos nativos de las bibliotecas cargadas, se utilizan stubs de métodos declarados con la palabra clave native.
Error UnsatisfiedLinkError: ¿Qué es y cuándo se produce?
Si un programa Java está utilizando una librería nativa pero es incapaz de encontrarla en tiempo de ejecución por alguna razón, lanza el error en tiempo de ejecución java.lang.UnsatisfiedLinkError. Más concretamente, este error se lanza siempre que la JVM es incapaz de encontrar una definición apropiada en lenguaje nativo de un método declarado nativo, mientras intenta resolver las bibliotecas nativas en tiempo de ejecución [2]. El error UnsatisfiedLinkError es una subclase de la clase java.lang.LinkageError lo que significa que este error es capturado al inicio del programa, durante el proceso de carga y enlace de clases de la JVM.
Algunas situaciones habituales en las que se produce este error incluyen una referencia a las bibliotecas ocijdbc10.dll y ocijdbc11.dll al intentar conectarse a una base de datos Oracle 10g u 11g con el controlador OCI JDBC [3], así como la dependencia de la biblioteca lwjgl.dll utilizada en el desarrollo de juegos y aplicaciones Java que dependen de algunas bibliotecas C/C++ heredadas.
Cómo solucionar el error UnsatisfiedLinkError
Para averiguar el culpable exacto y solucionar el error UnsatisfiedLinkError, hay que tener en cuenta un par de cosas:
- Asegúrese de que el nombre de la biblioteca y / o la ruta se especifican correctamente.
- Llame siempre a System.load() con una ruta absoluta como argumento.
- Asegúrese de que la extensión de la biblioteca está incluida en la llamada a System.load().
- Compruebe que la propiedad java.library.path contiene la ubicación de la biblioteca.
- Compruebe que la variable de entorno PATH contiene la ruta a la biblioteca.
- Ejecute el programa Java desde un terminal con el siguiente comando: java -Djava.library.path=«<LIBRARY_FILE_PATH>» -jar <JAR_FILE_NAME.jar>
Una cosa importante a tener en cuenta es que System.loadLibrary() resuelve los nombres de archivos de biblioteca de una manera dependiente de la plataforma, por ejemplo, el fragmento de código en el ejemplo en la Introducción esperaría un archivo llamado someLibFile.dll en Windows, someLibFile.so en Linux, etc.
Además, el método System.loadLibrary() busca primero en las rutas especificadas por la propiedad java.library.path, y luego por defecto en la variable de entorno PATH.
Ejemplo de Error UnsatisfiedLinkError
El código siguiente es un ejemplo de intento de cargar una biblioteca nativa llamada libraryFile.dll con el método System.loadLibrary() en una plataforma Windows OS. La ejecución de este código arroja el error en tiempo de ejecución UnsatisfiedLinkError con un mensaje que dice «no libraryFile in java.library.path» sugiriendo que no se pudo encontrar la ruta a la biblioteca .dll.
package rollbar;
public class JNIExample {
static {
System.loadLibrary("libraryFile");
}
native void libraryMethod(String arg);
public static void main(String... args) {
final JNIExample jniExample = new JNIExample();
jniExample.libraryMethod("Hello");
}
}Exception in thread "main" java.lang.UnsatisfiedLinkError: no libraryFile in java.library.path: C:\WINDOWS\Sun\Java\bin;C:\WINDOWS\system32;C:\WINDOWS;C:\Program Files (x86)\Common Files\Intel\Shared Files\cpp\bin\Intel64;C:\ProgramData\Oracle\Java\javapath;C:\WINDOWS\system32;C:\WINDOWS;C:\WINDOWS\System32\Wbem;C:\WINDOWS\System32\WindowsPowerShell\v1.0\;C:\Program Files\MySQL\MySQL Utilities 1.6\;C:\Program Files\Git\cmd;C:\Program Files (x86)\PuTTY\;C:\WINDOWS\System32\OpenSSH\;...
at java.base/java.lang.ClassLoader.loadLibrary(ClassLoader.java:2447)
at java.base/java.lang.Runtime.loadLibrary0(Runtime.java:809)
at java.base/java.lang.System.loadLibrary(System.java:1893)
at rollbar.JNIExample.<clinit>(JNIExample.java:6) Hay un par de enfoques para solucionar este error.
Enfoque #1: Actualizar la variable de entorno PATH
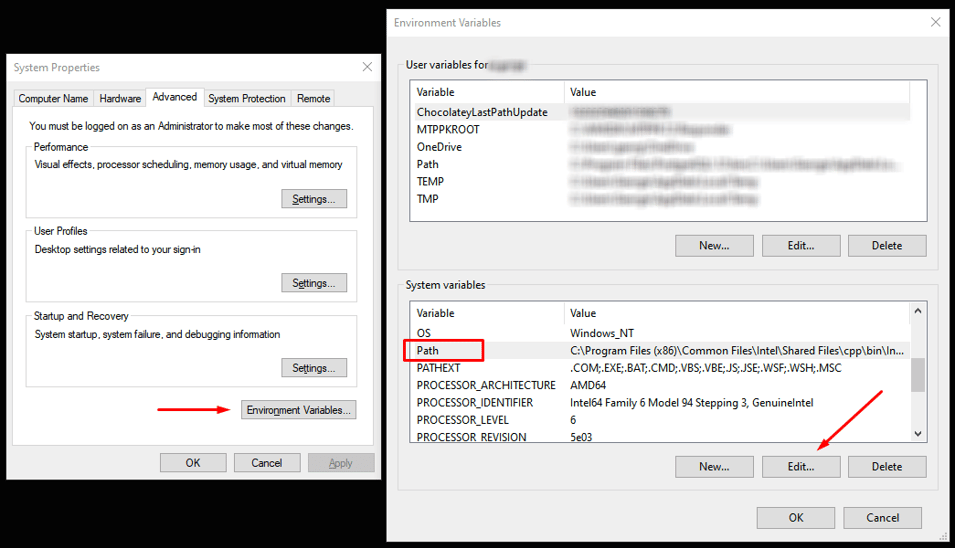
Uno es asegurarse de que la variable de entorno PATH contiene la ruta al archivo libraryFile.dll. En Windows, esto se puede hacer navegando a Panel de control → Propiedades del sistema → Avanzadas → Variables de entorno, encontrando la variable PATH (sin distinguir mayúsculas de minúsculas) en Variables del sistema, y editando su valor para incluir la ruta a la biblioteca .dll en cuestión. Para obtener instrucciones sobre cómo hacer esto en diferentes sistemas operativos, consulte.
Método 2: Comprobación de la propiedad java.library.path
Otro método consiste en comprobar si la propiedad del sistema java.library.path está establecida y si contiene la ruta a la biblioteca. Esto se puede hacer llamando a System.getProperty(«java.library.path») y verificando el contenido de la propiedad, como se muestra en el siguiente código.
package rollbar;
public class JNIExample {
static {
var path = System.getProperty("java.library.path");
if (path == null) {
throw new RuntimeException("Path isn't set.");
}
var paths = java.util.List.of(path.split(";"));
//paths.forEach(System.out::println);
if (!paths.contains("C:/Users/Rollbar/lib")) {
throw new RuntimeException("Path to library is missing.");
}
System.loadLibrary("libraryFile");
}
native void libraryMethod(String arg);
public static void main(String... args) {
final JNIExample jniExample = new JNIExample();
jniExample.libraryMethod("Hello");
}
}Exception in thread "main" java.lang.ExceptionInInitializerError
Caused by: java.lang.RuntimeException: Path to library is missing.
at rollbar.JNIExample.<clinit>(JNIExample.java:16)
Técnicamente, la propiedad java.library.path puede ser actualizada llamando a System.setProperty(«java.library.path», «./lib»), pero como las propiedades del sistema son cargadas por la JVM antes de la fase de carga de la clase, esto no tendrá efecto en la llamada System.loadLibrary(«libraryFile») que intenta cargar la biblioteca en el ejemplo anterior. Por lo tanto, la mejor manera de resolver el problema es seguir los pasos descritos en el enfoque anterior.
Método #3: Sobreescribiendo la propiedad java.library.path
Como complemento al enfoque anterior, la única forma efectiva de
establecer explícitamente la propiedad java.library.path es ejecutando
el programa Java con el argumento de línea de comandos -Dproperty=value,
como se muestra a continuación:
java -Djava.library.path=«C:\Users\Rollbar\lib» -jar JNIEjemplo
Y puesto que esto anularía la propiedad system si ya está presente,
cualquier otra librería requerida por el programa para ejecutarse
también debería incluirse aquí.
Método #4: Usar System.load() en lugar de System.loadLibrary()
Por último, sustituir System.loadLibrary() por una llamada a System.load() que tome la ruta completa de la biblioteca como argumento es una solución que evita la búsqueda en java.library.path y soluciona el problema independientemente de cuál fuera la causa inicial del error UnsatisfiedLinkError.
package rollbar;
public class JNIExample {
static {
System.load("C:/Users/Rollbar/lib/libraryFile.dll");
}
native void libraryMethod(String arg);
public static void main(String... args) {
final JNIExample jniExample = new JNIExample();
jniExample.libraryMethod("Hello");
System.out.println("Library method was executed successfully.");
}
}Library method was executed successfully.Sin embargo, no siempre es deseable codificar la ruta a la biblioteca, por lo que en esos casos es preferible recurrir a otros métodos.
Resumen
El uso de librerías nativas compiladas para diferentes plataformas es una práctica común en Java, especialmente cuando se trabaja con sistemas grandes y de características o rendimiento críticos. El marco de trabajo JNI permite a Java hacer esto actuando como puente entre el código Java y las bibliotecas nativas escritas en otros lenguajes. Uno de los problemas con los que se encuentran los programadores es la imposibilidad de cargar correctamente estas bibliotecas nativas en su código Java, momento en el que la JVM desencadena el error en tiempo de ejecución UnsatisfiedLinkError. Este artículo proporciona una visión de los orígenes de este error y explica los enfoques pertinentes para tratar con él.
Seguimiento, análisis y gestión de errores con Rollbar
Gestionar errores y excepciones en el código es todo un reto. Puede hacer que el despliegue de código de producción sea una experiencia desconcertante. Ser capaz de rastrear, analizar y gestionar errores en tiempo real puede ayudarle a proceder con más confianza. Rollbar automatiza la supervisión y clasificación de errores, lo que hace que corregir errores de Java sea más fácil que nunca. Inscríbase hoy mismo
Referencias
[1] Oracle, 2021. Java Native Interface Specification Contents, Introduction. Oracle and/or its affiliates. [Online]. Available: https://docs.oracle.com/javase/8/docs/technotes/guides/jni/spec/intro.html. [Accessed Jan. 11, 2022]
[2] Oracle, 2021. UnsatisfiedLinkError (Java SE 17 & JDK 17). Oracle and/or its affiliates. [Online]. Available: https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/lang/UnsatisfiedLinkError.html. [Accessed Jan. 11, 2022]
[3] User 3194339, 2016. UnsatisfiedLinkError: no ocijdbc11 in java.library.path. Oracle and/or its affiliates. [Online]. Available: https://community.oracle.com/tech/developers/discussion/3907068/unsatisfiedlinkerror-no-ocijdbc11-in-java-library-path. [Accessed Jan. 11, 2022]
[4] User GustavXIII, 2012. UnsatisfiedLinkError: no lwjgl in java.library.path. JVM Gaming. [Online]. Available: https://jvm-gaming.org/t/unsatisfiedlinkerror-no-lwjgl-in-java-library-path/37908. [Accessed Jan. 11, 2022]
[5] Oracle, 2021. How do I set or change the PATH system variable?. Oracle and/or its affiliates. [Online]. Available: https://www.java.com/en/download/help/path.html. [Accessed Jan. 11, 2022]
Artículo traducido para el blog de n4p5t3r
Orginal: https://rollbar.com/blog/java-unsatisfiedlinkerror-runtime-error/#




